劳力士:在C#中启用Unicode的词法分析生成器
快速生成易于使用的主要.NET编程语言词法分析器/扫描器
简介
词法分析通常是解析过程中的第一阶段。在我们能够分析结构化文档之前,我们必须将其分成称为令牌或词元的词法元素。大多数解析器都使用此方法,从词法分析器中获取令牌,并将其用作元素输入。词法分析器也可以在解析器之外使用,并且在诸如缩小器之类的工具中,甚至只需要在文档中查找模式的简单扫描器中使用它们,因为词法分析器基本上起到了复合正则表达式匹配器的作用。
Rolex 生成词法分析器,使这个过程变得轻松和相对直观,无论是在定义还是使用它们方面。Rolex 生成的代码使用了一个简单但可靠快速的 DFA 算法。所有匹配都在线性时间内完成。由于不回溯,所以您不能输入可能导致二次方时间复杂度的表达式。正则表达式很简单,不需要捕获组。没有锚点,因为它们会使匹配复杂化,并且在令牌生成器中没有太大用处。没有惰性表达式,但有一种定义多字符结束条件的方法,这正是惰性表达式的 80% 用途。
使用 Rolex 的主要优点是速度。生成的词法分析器非常快。使用 Rolex 的主要缺点,除了语法上稍有限制,是生成复杂词法分析器可能需要花费的时间。基本上,在构建期间,您会为 Rolex 的性能付费。
更新: 用更快的变体替换了 FA 引擎,以加快代码生成速度,并进行了一些错误修复。删除了 “原型” 选项。
更新 2: 进一步提高了 FA 引擎的性能,并添加了 externaltoken 功能。
更新 3: 简化了 DFA 表示-平整为 Int 数组。通过使用 GraphViz 渲染词法分析器的 DFA 和 NFA 图形的能力。
更新 4: 添加了图形输出,修复了代码生成中的错误,并改进了输出。
梳理这一团糟
Rolex 命令行界面
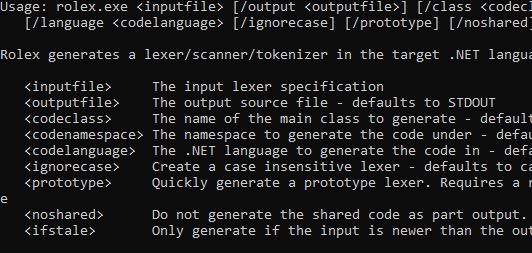
使用 Rolex 相对简单。以下是用法界面:
用法: rolex.exe <inputfile> [/output <outputfile>] [/class <codeclass>] [/namespace <codenamespace>] [/language <codelanguage> [/external <externaltoken>] [/ignorecase] [/noshared] [/ifstale] [/nfagraph <dfafile>] [/dfagraph <nfafile>] [/graph <graphfile>] [/dpi <dpi>]Rolex 会在目标 .NET 语言中生成一个词法分析器/扫描器/标记器。 <inputfile> 输入的词法分析器规范 <outputfile> 输出源文件,默认为标准输出 <codeclass> 要生成的主类的名称 - 默认从 <outputfile> 继承 <codenamespace> 基于之下的命名空间 - 默认为无 <codelanguage> 生成代码的 .NET 语言 - 默认从 <outputfile> 继承 <externaltoken> 如果要使用外部令牌,则为外部令牌的命名空间 - 默认为非外部 <ignorecase> 创建一个不区分大小写的词法分析器 - 默认为区分大小写 <noshared> 不作为输出的一部分生成共享代码 - 默认生成共享代码 <ifstale> 仅在输入较新时生成 <staticprogress> 不使用动态控制台功能进行进度指示 <nfafile> 错误新生成的 NFA 词法分析器图形写入到指定的图像文件中.* <dfafile>错误新生成的 DFA 词法分析器图形写入到指定的图像文件中.* <graphfile> 所有单独规则的 DFA 写入到图形中.* <dpi> 指定 DPI 的任何输出图形 - 默认为 300. * 需要安装 GraphViz 并在 PATH 中设置
inputfile(必填) – 指示要从中生成的词法分析器规范文件。下面将对此进行描述。outputfile– 指示要生成的输出代码文件,或默认为stdout。codeclass– 指示生成的分词器类的名称。默认情况下,它根据outputfile自动推导。codelanguage– 指示生成代码的语言。如果已指定outputfile扩展名,则基于该扩展名;否则默认为C#。codenamespace– 指示在代码下生成命名空间。默认没有命名空间。ignorecase– 指示整个规范应被视为不区分大小写,除非在某个规则上指定了ignoreCase=false。noshared– 指示不生成共享的依赖代码。默认情况下,Rolex将生成所有依赖代码作为分词器输出文件的一部分。如果正在生成多个分词器,你只需要共享代码的一个副本,只需为第二个及以后的分词器指定noshared,以避免重复代码而导致编译错误。externaltoken– 指示Rolex应使用给定命名空间中提供的令牌,而不是生成自己的。某些解析器提供了自己的令牌结构。默认情况下,生成自己的Token结构。ifstale– 指示在outputfile时间早于inputfile的情况下不进行生成。这在预构建步骤中非常有用,以便只有在输入发生更改时才重新构建输出。对于需要很长时间来生成的复杂词法分析器规范,这非常有用。nfagraph– 为词法分析器生成NFA状态机的图。主要用于调试表达式。dfagraph– 为词法分析器生成DFA状态机的图。graph– 生成每个规则(包括块结尾)的图。可能会很大。dpi– 生成的图的DPI(每英寸点数),默认为300。
Rolex词法分析器规范
词法分析器规范主要设计用于由其他工具(如 Parsley)生成。然而,如果你不害怕正则表达式,也可以手动使用它。
这是一种基于行的格式,每行形式类似于以下示例:
ident<id=1,ignoreCase>= '[A-Z_][0-9A-Z_]*'
或更一般地:
identifier [ "<" attributes ">" ] "=" ( "'" regexp "'" | "\"" literal "\"" )
每个属性是一个标识符,后面可选地跟有等号和JSON样式的字符串、布尔值、整数或其他值。如果未指定值,则为 true,这意味着 ignoreCase 为 true。请注意,字面表达式用双引号括起来,正则表达式用单引号括起来。
有几个可用的属性,如下所示:
id– 指示与此符号关联的非负整数ID。ignoreCase– 指示表达式应被解释为不区分大小写。hidden– 指示该符号应由词法分析器忽略,不进行报告。blockEnd– 指示指定符号的多字符结束条件。遇到此条件时,词法分析器将继续读取,直到找到blockEnd值,并将其消耗掉。这对于具有多个字符结束条件的表达式非常有用,例如C语言块注释、HTML/SGML注释和XML CDATA部分。这可以是正则表达式(单引号)或常量(双引号)。
规则在匹配的方面可能有些模糊。如果是这样,匹配的是规范中的第一条规则,按ID优先排序(从小到大),否则按文件顺序排序。
正则表达式语言支持基本的非回溯结构和常见字符类,以及与其.NET对应物相映射的[:IsLetter:]/[:IsLetterOrDigit:]/[:IsWhiteSpace:]/等等。请确保转义单引号,因为它们在Rolex中用于定界表达式。
生成的代码API
Rolex使用简单的API公开生成的词法分析器。每个词法分析器是一个类,该类中每个符号都声明为该类上的一个整数常量。构造词法分析器时,需要一个IEnumerator<char>,通常是一个字符串,但也可以是一个char[]数组或您实现的自定义源。或者,它将采用TextReader。词法分析器class支持对标记的foreach枚举,其信息使用Token struct返回。与此同时,Token struct分别在Line、Column、Position、SymbolId和Value中返回行、列、位置、符号和捕获信息。词法分析器类上的TabWidth属性允许您设置输入设备的制表位宽度,默认为4,以防它使用与此不同的宽度。这样可以准确返回列信息,以应对奇怪的设备情况。希望您可以将其保持不变。请注意,列和位置不是相同的东西!您的位置实际上是输入中的UTF-32代码点索引。如果您将字符串传递给词法分析器,当将Token.Position转换为int时,它不一定是字符串中的绝对索引。这是因为某些字符需要代理来表示它们。要获取字符索引,请使用Token.AbsoluteIndex。另一方面,Column属性是以1为基数的,就像Line一样,表示输入设备布局中的位置。这包括制表符、换行符和回车符。
让我们将我们所学都放在一起,进行一些词法分析。首先,让我们创建一个名为Example.rl的规范文件:
id='[A-Z_a-z][0-9A-Z_a-z]*'int='0|\-?[1-9][0-9]*'space<hidden>='[\r\n\t\v\f ]'lineComment<hidden>= '\/\/[^\n]*'blockComment<hidden,blockEnd="*/">= "/*"
以上,我们定义了id和int,其余都是隐藏的空白和注释。
现在,我们需要从Rolex中解析出一些代码:
Rolex.exe Example.rl /output ExampleTokenizer.cs /namespace RolexDemo
在我们的项目中包含ExampleTokenizer.cs后,我们可以像这样使用它:
var input = "foo bar/* foobar */ bar 123 baz -345 fubar 1foo *#( 0";var tokenizer = new ExampleTokenizer(input);foreach(var tok in tokenizer){ Console.WriteLine("{0}: {1} at column {2}", tok.SymbolId, tok.Value,tok.Column);}
这将在控制台输出:
0: foo,位于列10: bar,位于列40: bar,位于列201: 123,位于列240: baz,位于列281: -345,位于列320: fubar,位于列371: 1,位于列430: foo,位于列44-1: *,位于列48-1: #,位于列49-1: (,位于列501: 0,位于列52
使其工作的基础算法非常简单。它是基于DFA的算法,使用标准的幂集构造技术构建,修改为一次处理字符范围而不是一次处理字符,以便处理Unicode。最小化基于Hopcroft算法 (以前基于Huffman算法)。以前,我几乎没有用过所有这些内容,除了这个幕后的幂集构造技术,但是它无法处理Unicode。我以前认为这是不可行的,直到我看到其他库中的一些库-即Java中的”brics”及其C#端口”Fare”正在使用这种技术,但是它们的实现对我没有帮助,因为我们的代码有很大不同。最后,我自己解决了这个问题。我想知道它是可能的,我猜这就足够让我解决它。这是经过多年的研究。但是然后我发现我的解决方案不起作用!最终,我仔细研究了Fare代码,我从中了解到了足够多的工作原理,我能够使用自己的代码创建一个类似的方法。我已在这个受影响的单个源文件中包含了版权声明。至少它完成了。在Rolex中,我考虑使用Fare,但是在调查它时,看起来它根本不处理Unicode代理字符,而且错误处理很差,即使按照我的放松标准来看也是如此,所以我继续使用了我自己的实现。对于大型状态机,Fare可能会稍微更快一些,我知道它在处理大型字符集方面的速度要快得多,但它作弊,并且不能处理代理值。Rolex的正则表达式引擎内部是UTF-32的,所以它不会有这个问题,但是生成表格需要更长的时间。
不管怎样,问题解决了,我的更性感的解决方案,像我基于Pike虚拟机的lexer Lexly,无论我做了多少优化,都无法与老式的DFA在性能上竞争。DFA并不是很酷的技术。它们不是”小字节码解释器”之类的东西。它们大多是无聊的。但是它们能够完成任务,并且快速,这就是我们想要的。
正如我之前提到的,除了编写代码需要花费更长的时间之外,主要的劣势是它们无法很容易地支持像锚点、惰性匹配和捕获组之类的复杂结构,除非”黑客攻击” DFA 算法。对于标记分析器来说,这些功能并不重要。惰性匹配可能重要,但Rolex提供了另一种选择。
在速度上,这种权衡是值得的。Rolex的词法分析速度大约是基于NFA的Lexly lexer的10倍,而且比手动调优的基于DFA的Lexly lexer快两倍,仅仅是因为它不必托管一个复杂的虚拟机来运行它。
它仍然使用Deslang/Slang技术来渲染代码,但我已经将其从Build Pack中分离出来,并且只是在解决方案文件夹中包含了deslang.exe工具来满足预构建步骤。它负责将Export文件夹的内容转换为包含该文件夹中代码文件的所有CodeDOM表示的Deslanged.cs代码。请注意,该文件夹中的文件不是完整的C#代码,而是Slang,一种符合CodeDOM的C#子集。如果你修改它们,如果你不知道如何使用它,可能会导致问题。
历史
- 2020年1月25日 – 初始提交
- 2020年2月4日 – 修复了FA.Parse()中的一个错误
- 2020年2月11日 – 提高了生成速度,在FA.Parse()中修复了另一个错误
- 2020年2月25日 – 提高了生成速度,添加了”externaltoken”功能
- 2023年11月18日 – 简化了表格,添加了选项,修复了一些小错误
- 2023年11月20日 – 修复了一个小错误,添加了选项,改进了代码生成







Leave a Reply