如何使用“分段任何事物模型(SAM)”创建遮罩
嘿!你知道那些关于特斯拉自动驾驶技术的未来感和无人驾驶的喧闹吗?你是否想过它是如何实现魔术般的功能?那么,让我来告诉你-全靠图像分割和物体检测什么是图像分割?图像分割就是将一张图像切割成小块
嘿!你知道吧,那些关于特斯拉自动驾驶什么先进和无人驾驶的话题?你有没有想过它究竟是如何实现的?那么让我告诉你——这完全依靠图像分割和目标检测。
什么是图像分割?
图像分割,简单来说就是将图像切割成不同的部分,以帮助系统识别物体。它可以确定人类、其他车辆和道路上的障碍物的位置。这就是确保自动驾驶汽车安全行驶的技术。很酷,对吧? 🚗
在过去的十年里,计算机视觉取得了巨大的进步,特别是在制定超高级别的分割和目标检测方法方面。
这些突破的应用范围广泛,可以用于医学图像中的肿瘤和疾病检测、农业中的农作物监测,甚至是机器人导航。这项技术正在不同领域产生重大影响。
最主要的挑战在于获取和准备数据。构建图像分割数据集需要对大量图像进行注释标签定义,这是一项巨大的任务。这需要大量的资源。
当Segment Anything Model (SAM)(一切分割模型)出现时,游戏规则改变了。SAM通过使任何人都能够在不依赖标记数据的情况下为其数据创建分割掩模,从而革新了这个领域。
在本文中,我将指导你了解SAM,它的工作原理以及如何使用它来创建掩模。所以,准备好你的咖啡杯,我们要开始了! ☕
前提条件:
本文的前提条件包括基本的Python编程理解和基本的机器学习知识。
此外,熟悉图像分割概念、计算机视觉和数据注释挑战也会有所帮助。
什么是Segment Anything Model?
SAM是由Facebook的研究团队(Meta AI)开发的大型语言模型。该模型使用了一个庞大的11亿个分割掩模的数据集(SA-1B数据集)进行训练。由于该模型训练时使用了非常多样化的数据集并且具有低方差,因此它能够很好地泛化到未见过的数据。
SAM可以用于分割任何图像并创建掩模,而不需要任何标记的数据。这是一项突破性的成果,因为在SAM之前无法实现完全自动化的分割。
SAM的独特之处在于它是一种可提示的分割模型。通过文本和交互操作,提示可以让你指导模型产生你想要的输出。你可以通过多种方式向SAM提供提示:点、边界框、文本甚至基础掩模。
SAM是如何工作的?
SAM使用基于Transformer的架构,就像大多数大型语言模型一样。让我们看看数据在SAM的不同组件中的流动过程。
图像编码器:当你将图像提供给SAM时,首先会将其发送到图像编码器。顾名思义,这个组件将图像编码成向量。这些向量代表从图像中提取出的低级(边缘、轮廓)和高级特征,如物体的形状和纹理。这里的编码器是一种视觉Transformer(ViT),它与传统的卷积神经网络相比有许多优势。
提示编码器:用户提供的提示输入通过提示编码器转换为嵌入。SAM对于点、边界框提示使用位置嵌入,对于文本提示使用文本编码器。
掩模解码器:接下来,SAM将提取的图像特征和提示编码映射为生成的掩模,也就是我们的输出。SAM会为每个输入提示生成3个分割掩模,为用户提供选择。
为什么要使用SAM?
使用SAM,你可以跳过通常需要的昂贵设置,仍然能够获得快速的结果。它适用于各种类型的数据,如医学图像或卫星图像,并且可以轻松适配你已经用于快速检测任务的软件。
你还可以获得针对特定工作的工具,如图像分割,并且它易于使用,无论是训练还是分析数据。此外,它比以前的CNN系统更快,为你节省时间和金钱。
如何安装和设置SAM
现在您已经了解了SAM的工作原理,让我向您展示如何安装和设置它。第一步是使用以下命令在您的Jupyter笔记本或Google Colab中安装软件包:
pip install 'git+https://github.com/facebookresearch/segment-anything.git'/content Collecting git+https://github.com/facebookresearch/segment-anything.git 正在克隆 https://github.com/facebookresearch/segment-anything.git 到 /tmp/pip-req-build-xzlt_n7r 运行命令 git clone --filter=blob:none --quiet https://github.com/facebookresearch/segment-anything.git /tmp/pip-req-build-xzlt_n7r 已解析 https://github.com/facebookresearch/segment-anything.git 为提交 6fdee8f2727f4506cfbbe553e23b895e27956588 正在准备元数据 (setup.py) ... 完成下一步是下载您想要使用的SAM模型的预训练权重。
您可以从三个选项中选择检查点权重:ViT-B(91M)、ViT-L(308M)和ViT-H(636M个参数)。
如何选择正确的模型?参数数量越大,推理所需的时间越长,也就是生成遮罩所需的时间。如果您的GPU资源有限且需要快速推理,请选择ViT-B。否则,请选择ViT-H。
请按照以下命令设置模型检查点路径:
!wget -q https://dl.fbaipublicfiles.com/segment_anything/sam_vit_h_4b8939.pthCHECKPOINT_PATH='/content/weights/sam_vit_h_4b8939.pth'import torchDEVICE = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')MODEL_TYPE = "vit_h"模型权重已准备好!现在,我将向您展示在接下来的部分中,如何使用不同的方法提供提示并生成遮罩。🚀
SAM如何自动生成遮罩
SAM可以自动将整个输入图像分割成不同的段落,而不需要特定的提示。为此,您可以使用SamAutomaticMaskGenerator实用程序。
按照以下命令导入并使用模型类型和检查点路径进行初始化。
from segment_anything import sam_model_registry, SamAutomaticMaskGenerator, SamPredictorsam = sam_model_registry[MODEL_TYPE](checkpoint=CHECKPOINT_PATH).to(device=DEVICE)mask_generator = SamAutomaticMaskGenerator(sam)例如,我在笔记本中上传了一张狗的图片。这将是我们的输入图像,必须将其转换为RGB(红绿蓝)像素格式以输入模型。
您可以使用OpenCV Python软件包来完成这一点,然后使用generate()函数来创建遮罩,如下所示:
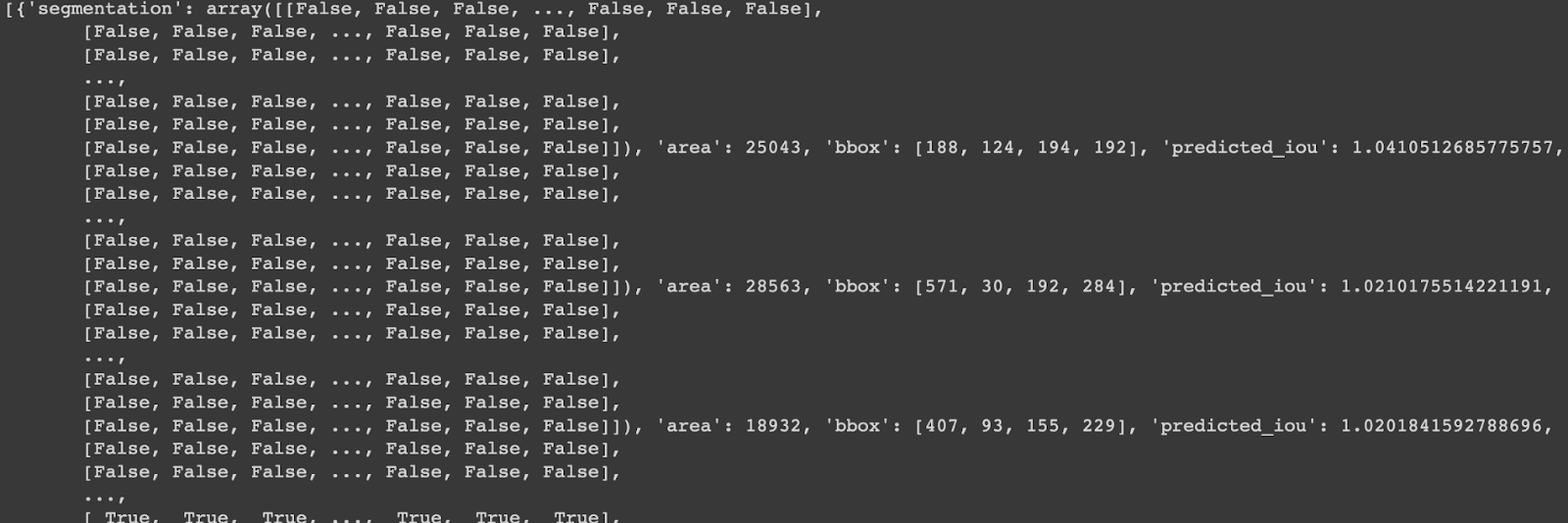
# 导入OpenCV软件包import cv2# 给出您的图像路径IMAGE_PATH= '/content/dog.png'# 从路径读取图像image= cv2.imread(IMAGE_PATH)# 转换为RGB格式image_rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)# 生成分割遮罩output_mask = mask_generator.generate(image_rgb)print(output_mask)生成的输出是一个包含以下主要值的字典:
Segmentation:一个具有遮罩形状的数组area:以像素为单位存储遮罩的面积的整数bbox:边界框的坐标[xywh]Predicted_iou:IOU是用于分割的评估分数
那么我们如何可视化输出遮罩呢?
嗯,这是一个简单的Python函数,它将以SAM生成的字典作为输出,并绘制带有掩码形状值和坐标的分割掩码。
# 输入输出并绘制图像和掩码的函数def show_output(result_dict,axes=None): if axes: ax = axes else: ax = plt.gca() ax.set_autoscale_on(False) sorted_result = sorted(result_dict, key=(lambda x: x['area']), reverse=True) # 为每个段落面积绘制图像 for val in sorted_result: mask = val['segmentation'] img = np.ones((mask.shape[0], mask.shape[1], 3)) color_mask = np.random.random((1, 3)).tolist()[0] for i in range(3): img[:,:,i] = color_mask[i] ax.imshow(np.dstack((img, mask*0.5)))让我们使用这个函数来绘制我们的原始输入图像和分割掩码:
_,axes = plt.subplots(1,2, figsize=(16,16))axes[0].imshow(image_rgb)show_output(sam_result, axes[1])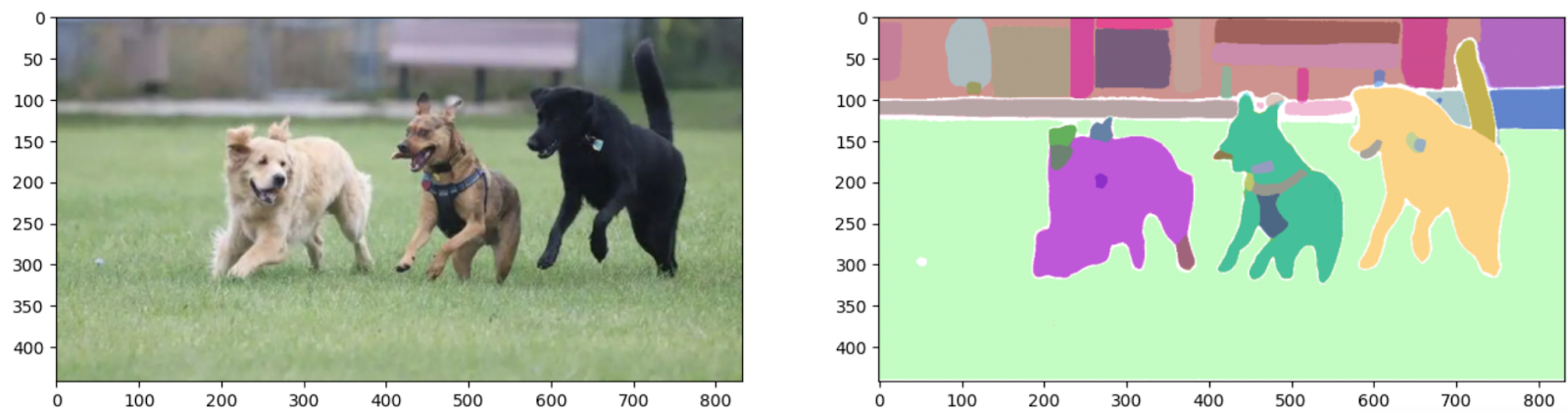
正如您所看到的,该模型使用零射方法一次性分割了图像中的每个对象!🌟
如何使用带有边界框提示的SAM
有时,我们可能只想对图像的特定部分进行分割。为了实现这一点,输入粗略的边界框以识别感兴趣区域内的对象,并由SAM相应地对其进行分割。为此,导入并初始化SamPredictor,并使用set_image()函数传递输入图像。然后,调用predict函数,将边界框坐标作为box参数的输入,如下面的代码片段所示。边界框提示应采用[X-min,Y-min,X-max,Y-max]格式。
# 使用编码后的图像设置SAM模型mask_predictor = SamPredictor(sam)mask_predictor.set_image(image_rgb)# 使用边界框提示预测掩码masks,scores,logits = mask_predictor.predict(box=bbox_prompt,multimask_output=False)# 绘制边界框提示和预测的掩码plt.imshow(image_rgb)show_mask(masks[0], plt.gca())show_box(bbox_prompt, plt.gca())plt.show()
如何使用点作为SAM的提示
如果您需要图像中某个点的对象掩码,您可以将点的坐标作为输入提示提供给SAM。然后,模型将生成三个最相关的分割掩码。这对于感兴趣的主要对象存在任何不确定性情况非常有帮助。
第一步与我们在之前的部分中所做的类似。使用输入图像初始化预测模块。然后,将输入提示作为[X,Y]坐标提供给参数point_coords。
# 使用输入图像初始化模型from segment_anything import sam_model_registry, SamPredictorsam = sam_model_registry[MODEL_TYPE](checkpoint=CHECKPOINT_PATH).to(device=DEVICE)mask_predictor = SamPredictor(sam)mask_predictor.set_image(image_rgb)# 将点作为输入提示 [X,Y]-坐标input_point = np.array([[250, 200]])input_label = np.array([1])# 预测该点的分割掩码masks,scores,logits = mask_predictor.predict(point_coords=input_point,point_labels=input_label,multimask_output=True,)由于我们将multimask_output参数设为True,所以会有三个输出掩码。让我们通过绘制掩码和其输入提示来进行可视化。

我还打印了每个掩码的自评IOU分数。IOU代表交并比,用于衡量物体轮廓与掩码之间的偏差。
结论
通过收集原始图像并利用SAM工具进行标注,您可以为您的领域构建定制的分割数据集。该模型在噪声或遮挡等复杂条件下也表现出一致的性能。
在即将推出的版本中,他们将使文本提示兼容,旨在提高用户友好性。
希望这些信息对您有所帮助!
谢谢您的阅读!我是Jess,也是Hyperskill的专家。您可以在平台上查看我们的机器学习课程。










Leave a Reply