开始使用Quarkus和JPAStreamer
开始使用Quarkus和JPAStreamer
注意:本文由Julia Gustafsson撰写。
在软件开发世界中,创新通常以改变我们构建应用程序的强大工具的形式到来 – 那就是Quarkus,一个正在重塑Java领域的开发平台。
如果您是Quarkiverse的新手,本教程是开始探索如何彻底改善您的Java开发经验的绝佳途径。我将向您展示如何快速在Quarkus平台上组装一个REST应用程序,利用JPAStreamer的强大功能,该功能是一个处理数据库交互的Hibernate扩展,具备Java Stream API的优雅之处。
在完成本指南后,您将掌握无缝进行云部署的Java应用程序的技巧。而且,如果您发现Java中具备实时代码重新加载和持续测试功能会更加愉快,我将不会感到惊讶。
如果您喜欢视觉指南,这个教程的视频版本在freeCodeCamp.org的YouTube频道上有 zh.codescode.com/hacktoberfest-2023-contributors.html (大约1小时)。
1. 我们将构建什么
本教程是构建一个强大的Quarkus应用程序的综合指南。我们将覆盖每一个重要方面,从设置开发环境和建立数据库连接,到定义REST端点,使用JPAStreamer进行强大查询的Java Streams,轻松进行持续测试,以及实现原生编译。最终的结果是一个轻量级的REST应用程序,在冷启动后的一瞬间即可提供有关示例影片的信息,为您未来的Quarkus项目打下基础。
表面上看,这似乎只是另一个开发应用程序的指南,但实际上,它也是开发Quarkus的一瞥。
在开发过程中,您将熟悉以下主题:
- 设置Quarkus项目
- 连接到MySQL Docker实例
- 使用Quarkus开发模式
- 使用JPAStreamer将查询表达为Java Streams
- 进行持续测试
- 通过原生编译实现快速启动时间和最小内存消耗
1.1 Quarkus有何特殊之处?
Quarkus通常被描述为用于现代Java和Kotlin应用程序的尖端云原生框架。它的使命是解决长时间启动时间、高内存消耗和相对较慢的开发经验等长期存在的Java难题。
它通过两个巧妙的设计特点来实现这个目标 – 一种改进的构建过程,它在构建时完成大部分繁重的工作,而不是在应用程序启动时完成,以及作为其扩展的开发者模式,允许您即时启动应用程序并立即应用任何代码更新。
在初始发布四年后,Quarkus拥有广泛的扩展,确保与Hibernate,Spring和JUnit等主要Java库的无缝集成。
1.2 JPAStreamer是什么?
JPAStreamer是一个轻量级库,旨在简化使用Java持久性API(JPA)的Java应用程序中的数据库访问。它的优势在于其表达能力强大且类型安全的Stream查询,有助于提高编程的精确度和生产率。
JPAStreamer通过将管道转换为Hibernate查询语言(HQL)查询来优化性能。与在Hibernate中使用getResultStream()不同,它可以确保只获取相关实体,类似于直接使用SQL。
想象一下从数据库中获取10部电影,其中每个标题以”A”开头并且至少1小时长。使用JPAStreamer,查询就如下所示:
List<Film> films = jpaStreamer.stream(Film.class).filter(Film$.title.startsWith("A").and(Film$.length.greaterThan(60)).limit(10).collect(Collectors.toList());2. 先决条件
在我们开始编码之前,确保您已经准备好了所需的一切非常重要。虽然本指南涵盖了获得完全功能的应用程序所需的所有详细信息,但假设您已经:
- 熟悉基本Java
- 了解Java Stream API
- 熟悉使用JPA/Hibernate进行数据库交互
如果您计划在本地机器上跟随操作,请确保您的开发环境满足以下要求:
- Java 11或更高版本
- 您喜欢的IDE(本指南使用IntelliJ)
- Maven(或Gradle)
- Quarkus CLI
- Docker和Docker CLI(或您自己的数据库)
- 可选项- GraalVM安装
3. 项目设置
一旦您检查了先决条件的清单,就可以创建一个新的Quarkus项目。有多种方法可以实现这一点,但为了简单起见,我将使用在code.quarkus.io/上找到的Quarkus项目配置器。此工具可以帮助您快速创建一个完整的构建文件,并具备必要的依赖项。
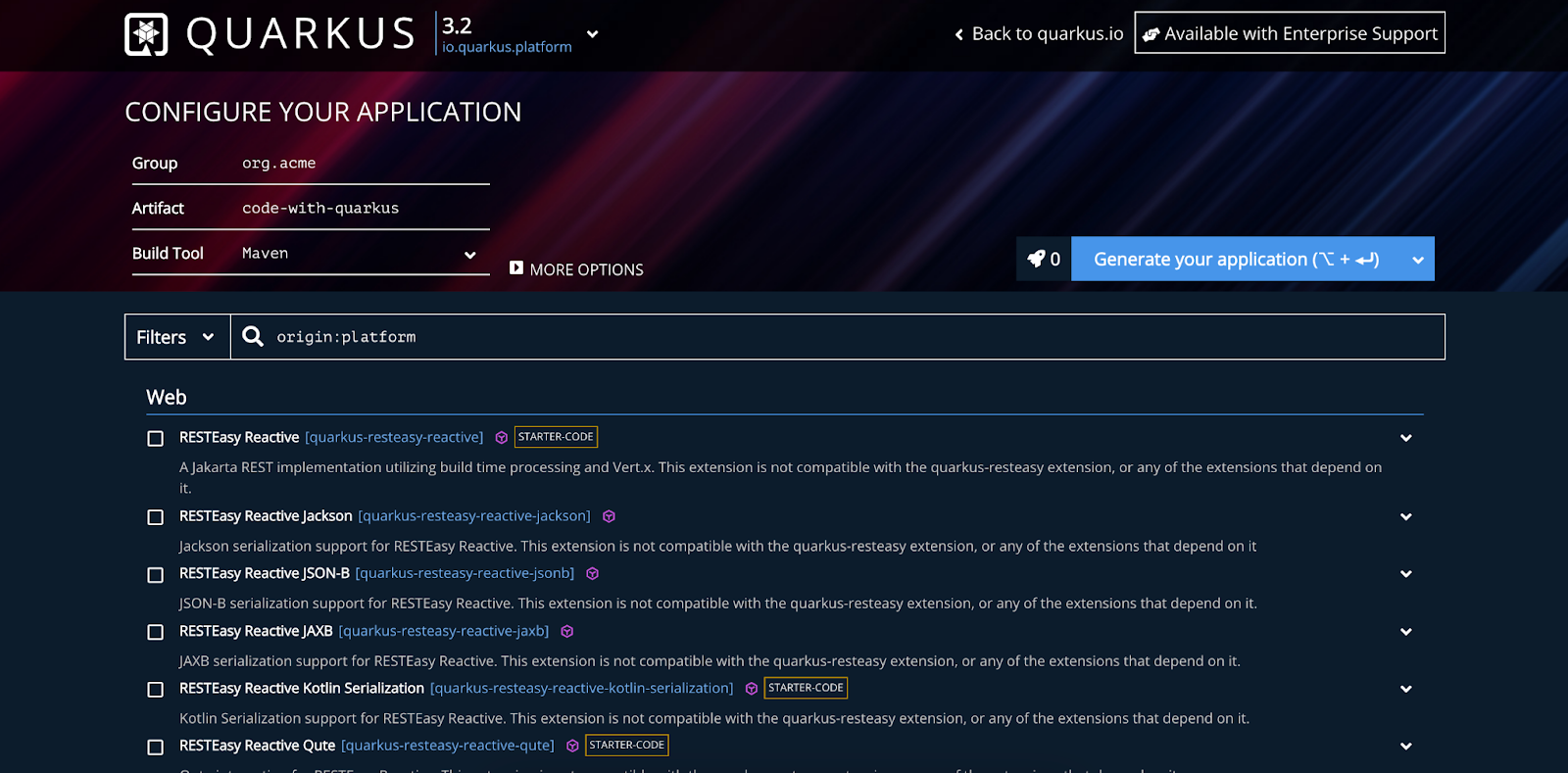
首先,在页面顶部选择一个Quarkus版本。我建议使用最新版本或选择LTS版本,例如3.2(时间写作时的最新版本)。适当地为您的项目命名后,继续选择以下依赖项:
- Hibernate ORM with Panache:用于处理数据库交互
- JPAStreamer: 直观且类型安全的Hibernate扩展查询
- SmallRye OpenAPI: 用于发送测试请求的Swagger UI
- RESTEasy Reactive Jackson: 便捷设置REST端点
- JDBC Driver – MySQL:我们的数据库驱动程序
然后只需点击“生成您的应用程序”以下载项目ZIP文件。您可以通过此链接下载一个具有相同设置的Quarkus入门示例。
从这里,使用您喜欢的IDE打开项目。快速查看项目结构,您会注意到Quarkus按照熟悉的Maven结构组织了项目,其中包含一个用于依赖项和项目配置的pom.xml文件。
quarkus-tutorial |- src | |- main | | |- java | | |- resources |- src如果您查看pom.xml文件,您将找到所选的依赖项。同时请注意,JUnit会自动添加到后续的持续测试阶段。
4. 数据库设置
在涉足新技术领域时,我经常在开发环境中包含Oracle的示例数据库Sakila,因为它可以轻松地作为Docker镜像使用。这个项目也不例外。
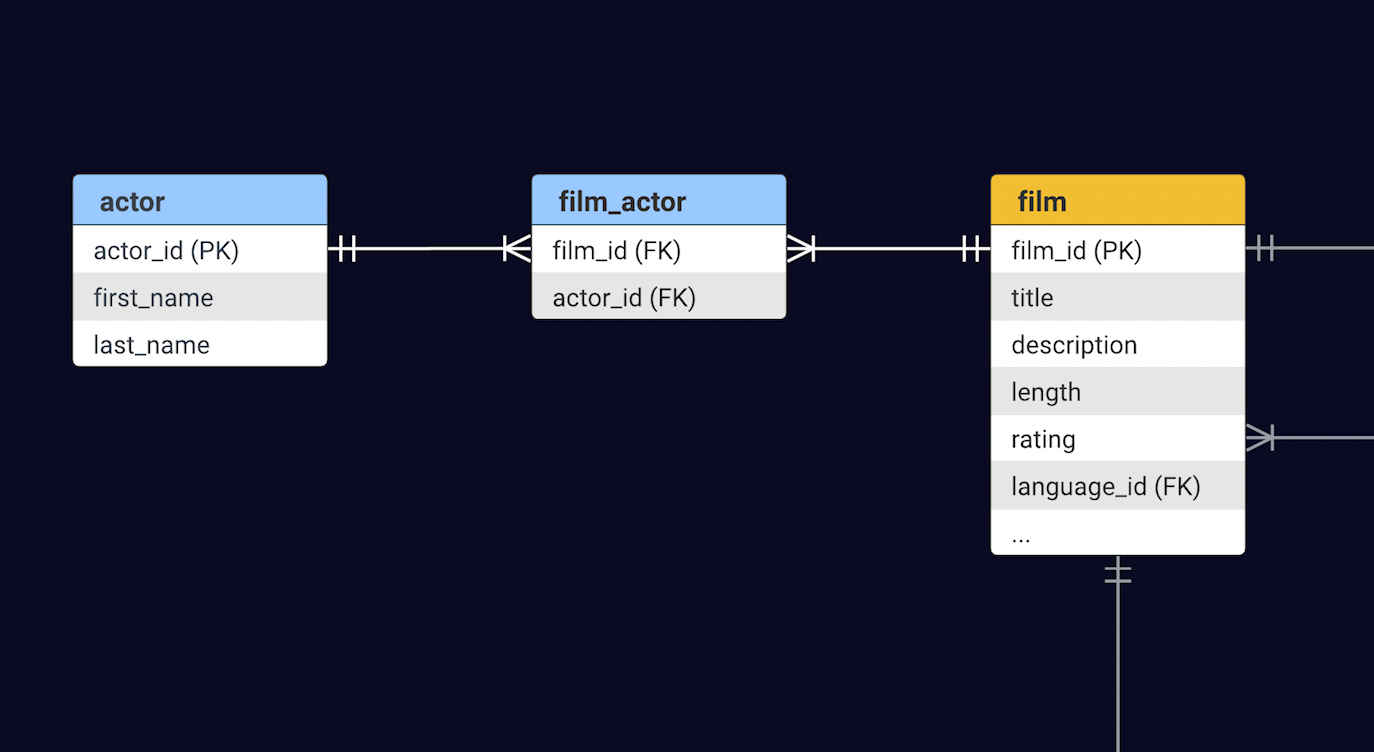
Sakila模拟了一个老式的视频租赁店,其中您会热切地等待磁带或DVD上的电影。自然地,这个数据库的核心围绕着Film表展开,支持各种支持性表-比如库存(Inventory)、客户(Customer)和支付(Payment)。对于本演示,我们的重点将放在提供有关电影和出演电影的演员的信息上。Film和Actor表之间存在着多对多的关系-一个电影可以有多个演员,反之亦然,一个演员可以出演多部电影。
要在端口3306上下载和启动数据库,请使用Docker CLI。
docker run --platform linux/amd64 -d --publish 3306:3306 --name sakila restsql/mysql-sakila
--platform标志指示Docker接受Sakila Linux AMD64镜像,无论本地平台如何。根据我的经验,在其他平台上也可以正常运行。
运行此命令后,您应该观察到图像正在下载和启动。
5. Hibernate设置
为了通过Hibernate方便地进行数据库交互,需要进行一些设置。虽然在Quarkus领域中的Hibernate行为与任何Java应用程序中的标准Hibernate非常相似,但您将在application.configuration文件中配置Hibernate。 其次,我们将借助IntelliJ生成JPA样板。
5.1 配置Hibernate
application.configuration文件位于您最初下载的项目模板的/resources文件夹中。该文件作为一个中心,为各种潜在的Quarkus依赖和扩展提供服务。这意味着我们的数据库配置不会是特定于Hibernate的;任何需要进行数据库交互的框架都可以使用这个配置。
然而,设置与常规Hibernate数据库配置类似。假设您按照指示运行Sakila数据库,您需要定义MySQL JDBC驱动程序,指定localhost上端口3306的JDBC URL,并提供用户名‘root’和密码‘sakila’。
quarkus.datasource.jdbc.driver=com.mysql.cj.jdbc.Driver
quarkus.datasource.jdbc.url=jdbc:mysql://localhost:3306/sakila
quarkus.datasource.username=root
quarkus.datasource.password=sakila此外,我建议设置hibernate-orm.log.sql为true,因为这将确保记录所有Hibernate查询,简化以后检查JPAStreamer查询的过程。
quarkus.hibernate-orm.log.sql=true
5.2 创建JPA元模型
为了操作数据,您需要一个带有Entity代表每个表的JPA模型。由于这不是一篇深入的Hibernate指南,我建议您走捷径,生成一些只需要稍加修改即可满足您需求的JPA样板。如果您使用的是IntelliJ,您可以按照我的脚步进行操作,否则您将不得不查阅您的IDE文档。
首先,在IntelliJ中连接到数据库,方法是导航到文件 > 新建 > 数据源,并选择一个MySQL实例。然后,使用与上一节配置Hibernate中相同的连接URL、用户名和密码填充对话框中的字段。
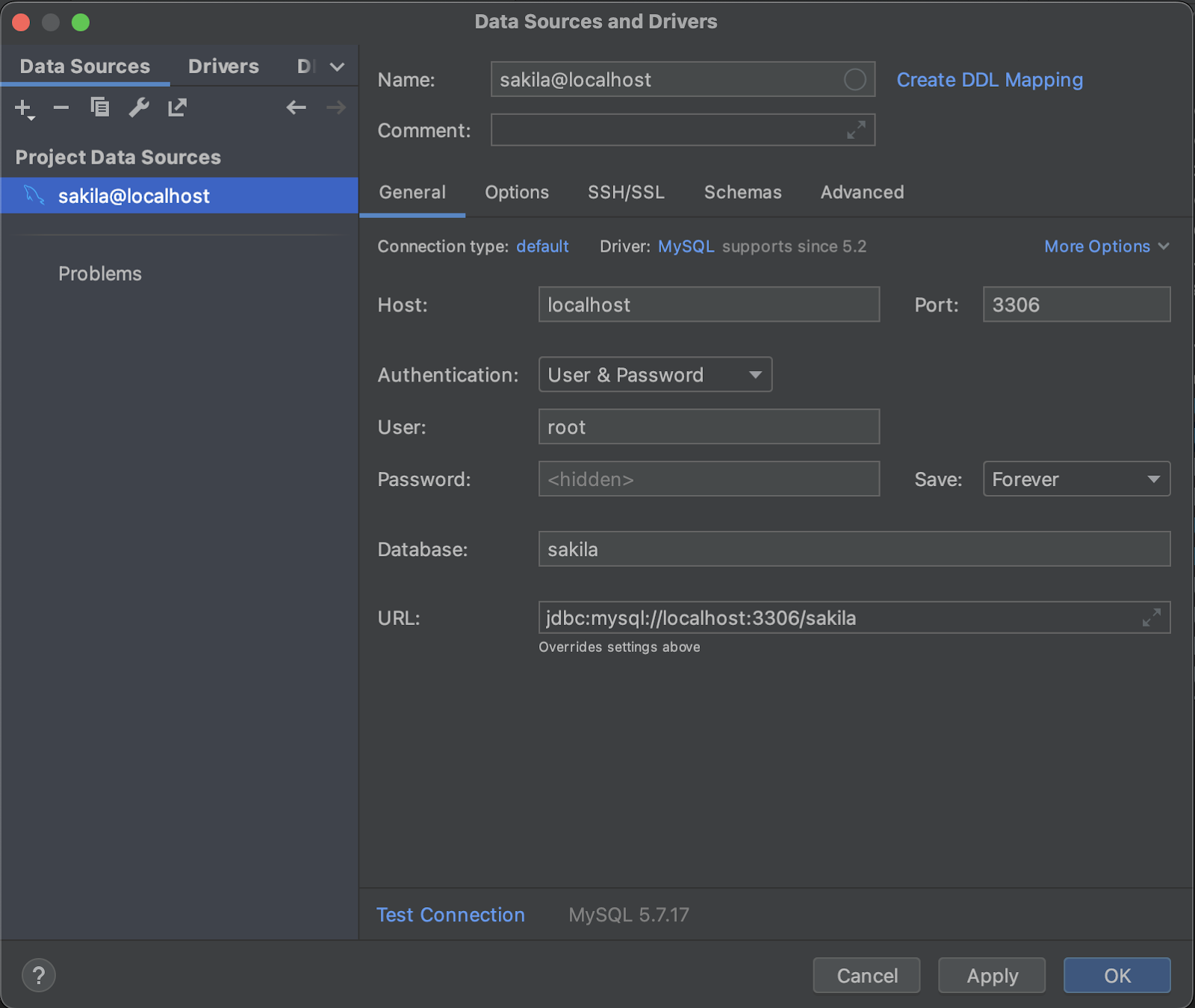
按下OK后,您应该能够查看数据库的内容,以确认连接是否正确建立。如果连接后数据库显示为空,请触发数据库重新加载,以确保表数据正确获取。
现在,我们的数据库已经与IntelliJ链接在一起,生成实体非常简单。在连接的数据库上右键单击,然后选择“生成持久映射”。选择要放置生成的实体的位置(一个包),并取消选择所有表,除了Film和Actor,因为这两个表是我们将要处理的唯一表。再次点击OK,这些表的JPA实体将在一瞬间生成。
接下来,您需要对生成的类进行一些修改。JPA提供了许多注释来对这些映射进行微调,但我只会介绍对于此应用程序而言必要的内容。
首先,声明这两个生成的类映射到哪个表和模式,如下所示:
@Table(name = "film", schema = "sakila")
public class Film { … }
@Table(name = "actor", schema = "sakila")
public class Actor { … }然后要么从Film类中删除rating和special_features字段,要么改进映射以对值施加一些约束,如下所示:
@Basic@Column(name = "rating", columnDefinition = "enum('G','PG','PG-13','R','NC-17')")private String rating;@Basic@Column(name = "special_features", columnDefinition = "set('Trailers', 'Commentaries', 'Deleted Scenes', 'Behind the Scenes')")private String specialFeatures;您还需要手动定义Film和Actor表之间的多对多关系。这需要对两个类进行一些更新。
首先,Film实体需要一个名为”actors”的字段,用于存储特定电影中出现的演员的引用。这通过@ManyToMany映射和@JoinTable注解来建立连接。请回顾上面数据库介绍中模式中的join_table和外键的名称。
@ManyToMany(cascade = { CascadeType.PERSIST, CascadeType.MERGE })@JoinTable( name = "film_actor", joinColumns = { @JoinColumn(name = "film_id") }, inverseJoinColumns = { @JoinColumn(name = "actor_id") })private List<Actor> actors = new ArrayList<>();同样,Actor类需要一个字段films来存储演员出演的电影集合。由于在Actor类中已经描述了连接,所以该字段只需要引用上述映射即可:
@ManyToMany(mappedBy = "actors")private Set<Film> films = new HashSet<>();最后一步,为Film和Actor类中的所有字段生成getter和setter方法。您可以选择手动完成或使用IntelliJ生成它们。
6. JPAStreamer设置
JPAStreamer使您能够创建复杂的Java Stream查询。为了在执行时将这些流转换为SQL查询,JPAStreamer利用其专用的元模型创建可读的谓词。虽然标准的lambda可以用于过滤,但它缺少JPAStreamer转换流管道为查询所需的细节。
在上面的示例中,您会注意到使用了名为Film$的实体。此实体属于JPAStreamer元模型,并允许您表达JPAStreamer理解的这些直接的谓词。
List<Film> films = jpaStreamer.stream(Film.class) .filter(Film$.title.startsWith("A") .and(Film$.length.greaterThan(60)) .limit(10) .collect(Collectors.toList());值得庆幸的是,一旦您拥有JPA元模型,JPAStreamer元模型将自动为您创建。因此,只需继续重建您的应用程序。
元模型位于目标目录中,这意味着默认情况下不会将其检测为源代码。为了解决这个问题,您需要通过右键单击将generated-sources文件夹指定为“生成的源根目录”。如果一切顺利,您的generated-sources文件夹应该包含Film$.class和Actor$.class。
请注意,如果您随时修改JPA模型,您需要重新构建项目以将更改与JPAStreamer元模型同步。还值得一提的是,生成的元模型的名称和位置可以使用环境变量属性进行定制。您可以在JPAStreamer文档中了解如何完成这个任务。
7. 应用架构
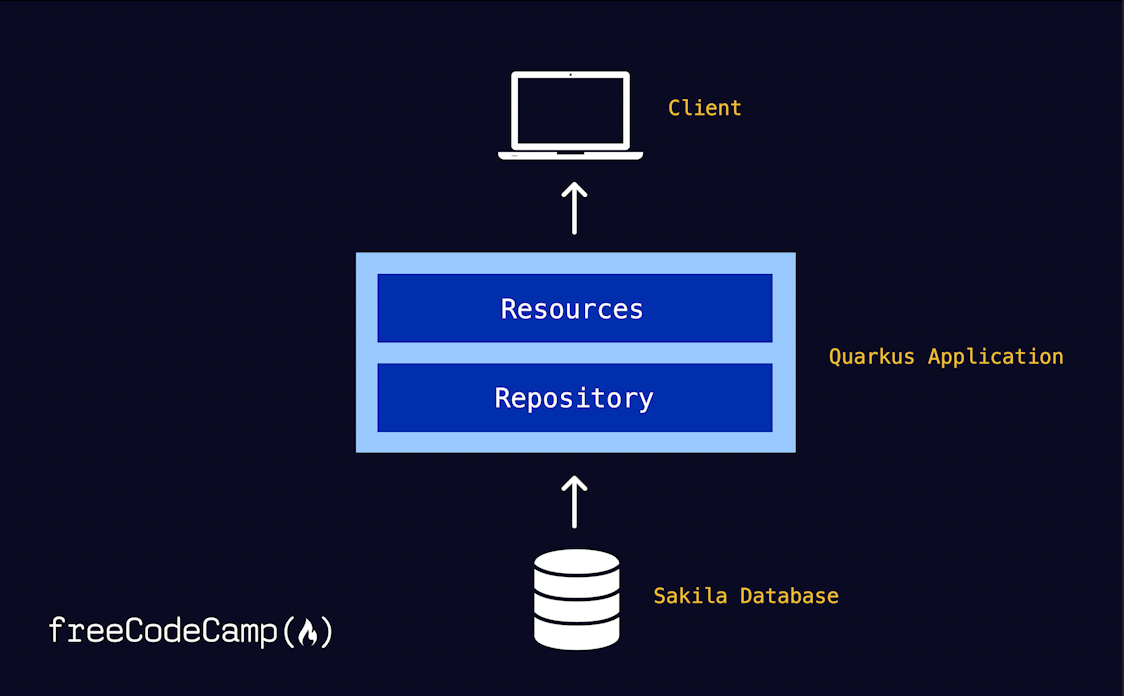
现在是时候来看应用架构了。目标是为客户端提供与电影相关的信息的端点。为了清晰和关注点分离,我选择采用了一个简单的Repository模式。
下面是当您完成后架构各个组件如何配合的示意图。Resources类负责将数据库派生的内容交付给客户端。但是,这个类不进行实际的数据库交互;相反,这个任务委托给Repository。这种架构方法将数据层与应用程序的其他方面明确地分离开来。
一旦你完成,这将在你的项目文件夹中转化为以下文件层次结构:
quarkus-tutorial |- src | |- main | | |- java | | | |- com.freecodecamp.app | | | | |- FilmResource.java | | | | |- model | | | | |- Film.java | | | | |- Actor.java | | | | |- repository | | | | |- FilmRepository.java | | |- resources | | | | |- application.properties|- src7. 你好,世界!
为了掌握使用Quarkus进行开发的节奏,让我们从创建一个经典的“Hello World”端点开始。
首先,建立位于数据模型包之上的FilmResource类:
@Path("/")public class FilmResource { @GET @Path("/hello") @Produces(MediaType.TEXT_PLAIN) public String helloWorld() { return "Hello world!"; }}@Path注解确保在应用程序启动时启动您的Resteasy servlet,并为请求打开端点/hello。
8. 在Quarkus开发模式下运行
有了一个简单的端点,我建议您启动应用程序以验证功能,并享受Quarkus开发模式的体验。在终端中使用以下命令启动应用:
quarkus dev
应用程序启动时,您应该会看到Quarkus提示,指示您的应用程序正在默认端口8080上运行,并且已激活实时编码。
Listening for transport dt_socket at address: 5005__ ____ __ _____ ___ __ ____ ______ --/ __ \/ / / / _ | / _ \/ //_/ / / / __/ -/ /_/ / /_/ / __ |/ , _/ ,< / /_/ /\ \--\___\_\____/_/ |_/_/|_/_/|_|\____/___/2023-08-14 14:14:01,731 INFO [io.quarkus] (Quarkus Main Thread) quarkus-tutorial 1.0.0-SNAPSHOT on JVM (powered by Quarkus 3.1.3.Final) started in 2.210s. Listening on: http://localhost:80802023-08-14 14:14:01,733 INFO [io.quarkus] (Quarkus Main Thread) Profile dev activated. Live Coding activated.您现在可以访问http://localhost:8080/hello来确认您得到了预期的响应“Hello world!”。
如果这是您第一次使用Quarkus开发模式,请抓住机会复制您的第一个端点。即使是一个小小的改动,例如一个字符,也足以将其与原始版本区分开来。接下来,在终端中按下[s]键快速重新启动应用程序。重新启动将在瞬间完成,不久后您就可以在浏览器中访问新的端点。
这种动态的方法可以防止在编译后发现应用程序无法运行的可怕情况。您也不再需要忍受针对算法或代码片段的小调整而进行冗长编译的时间。这是一种非常迅速和灵活的交互式开发方法。
在我们继续之前,这里有几个基本的命令是值得知道的:
[s] - 强制重新启动[h] - 显示帮助[q] - 退出9. 使用Java Streams和JPAStreamer获取电影
到目前为止,我们的应用程序尚未涉及数据库,但这是我们的下一步。我们从简单开始,逐渐构建更强大的Stream查询。
通过在现有模型包旁边建立一个专用的repository包来启动这个过程。在这个repository部分中,创建一个名为FilmRepository的类。正如其名称所示,这个类将作为我们的数据库查询的中心。为了将其注入到FilmResource中,这个类需要被@ApplicationScoped注解。
然后,为了开始利用JPAStreamer,将其集成到repository中,注入一个JPAStreamer实例。这个实例将成为您访问Stream查询API的入口点。此时,您的类应该如下所示:
@ApplicationScopedFilmRepository() { @Inject JPAStreamer jpaStreamer; … }9.1 通过Id获取实体
第一个端点将根据id获取电影的标题。这是你利用JPAStreamer执行查询的第一个机会。你可以把Stream查询想象成一个虚拟的管道,所有在数据库中的电影都会流经它。追加到管道上的操作决定了哪些实体可以通过,并以什么形式通过。例如,过滤操作相当于WHERE语句,它对结果实体放置逻辑约束。
要启动一个Stream查询,你只需调用方法JPAStreamer.stream()并提供一个你选择的源。在这个例子中,我们的源是Film表,由实体Film.class表示。该操作的返回值是一个标准的Stream<Film>。这意味着你可以实际上应用Stream API中的任何可用的Stream操作来操作Film实体。
但是不要太快 – 你的Stream操作的选择对性能有很大影响,特别是对于大数据集!如果你熟悉Stream API,你可能已经遇到过许多基于lambda的谓词和映射的例子,如下所示:
.filter(f -> f.getFilmId().equals(filmId))
然而,这个谓词不能被JPAStreamer优化,因为这个匿名lambda拥有的元数据太少,无法做出正确的SQL翻译。因此,养成使用JPAStreamer元模型来表达谓词的习惯。在你的IDE中由IntelliSense引导,这很简单:
.filter(Film$.id.equal(filmId))
执行此操作时,实际上会将其转换为SQL WHERE操作,以确保过滤操作在数据库中执行,而不是在JVM中执行,以提高效率。
有了这个知识,你可以继续创建一个根据id获取电影的方法,如下所示:
public Optional<Film> film(int filmId) { return jpaStreamer.stream(Film.class) .filter(Film$.filmId.equal(filmId)) .findFirst();}与之前一样,使用[s]键在终端中重新加载应用程序,并浏览到:
如果一切正常,你将会看到电影的标题:
ANACONDA CONFESSIONS
在应用程序日志中快速查看将会显示JPAStreamer发出的Hibernate查询,确认了WHERE操作的存在。
Hibernate: select f1_0.film_id, f1_0.description, f1_0.language_id, f1_0.last_update, f1_0.length, f1_0.original_language_id, f1_0.rating, f1_0.rental_duration, f1_0.rental_rate, f1_0.replacement_cost, f1_0.special_features, f1_0.title from film f1_0 where f1_0.film_id=? limit ?9.2 分页查询
当处理大型数据集时,将整个结果发送给用户可能是不切实际甚至不可行的。这就是分页的作用,限制结果集的大小。利用Java Stream查询,分页变得简单。你可以使用skip()操作符跳过之前的数据并使用limit()限制结果集的大小。
假设每页大小为20,你可以方便地让客户端访问与指定长度匹配或超过指定长度的电影,并保持基于长度的有序序列。具体如下:
private static final int PAGE_SIZE = 20; ...public Stream<Film> paged(long page, int minLength) { return jpaStreamer.stream(Film.class) .filter(Film$.length.greaterThan(minLength)) .sorted(Film$.length) .skip(page * PAGE_SIZE) .limit(PAGE_SIZE);}为了适应这个分页内容,你的FilmResource需要一个新的端点:
@GET@Path("/paged/{page}/{minLength}")@Produces(MediaType.TEXT_PLAIN)public String paged(long page, int minLength) { return filmRepository.paged(page, minLength) .map(f -> String.format("%s (%d min)", f.getTitle(), f.getLength())) .collect(Collectors.joining("\n"));}一个简单的调用http://localhost:8080/paged/3/120将获取第三页的电影,每部电影最短持续时间为2小时,预计的回应如下:
美国马戏团(129分钟)绝地快递模特(129分钟)...巧克力鸭(132分钟)斯特里克里奇蒙特(132分钟)在Quarkus开发终端中快速查看,可以看到所有的流操作符都嵌入到查询中作为WHERE、ORDER BY和LIMIT操作符,分别有下限和上限值:
Hibernate: select f1_0.film_id, f1_0.description, f1_0.language_id, f1_0.last_update, f1_0.length, f1_0.original_language_id, f1_0.rating, f1_0.rental_duration, f1_0.rental_rate, f1_0.replacement_cost, f1_0.special_features, f1_0.title from film f1_0 where f1_0.length>? order by f1_0.length limit ?, ?9.3 投影
您可能已经注意到,您检索到了Film表的整个数组列,尽管在响应中只包括标题和长度。您可以通过使用投影作为流源而不是完整的表来节省应用程序资源。由于filmId是主键,所以它是必需的。
public Stream<Film> paged(long page, int minLength) { return jpaStreamer.stream(Projection.select(Film$.filmId, Film$.title, Film$.length)) .filter(Film$.length.greaterThan(minLength)) .sorted(Film$.length) .skip(page * PAGE_SIZE) .limit(PAGE_SIZE);}这个变化还要求您使用匹配的构造函数增强Film实体。
public Film(short filmId, String title, int length) { this.filmId = filmId; this.title = title; this.length = length;}现在,继续对paged端点进行第二次请求,并观察查询限制为三列。
http://localhost:8080/paged/3/120
Hibernate: select f1_0.film_id, f1_0.title, f1_0.length from film f1_0 where f1_0.length>? order by 3 limit ?, ?9.3 连接
现在进入一些更有趣的内容 – 执行流连接操作。连接是几个表的组合,转换为流查询,这意味着您需要更新流源以包括来自附加表的实体。
在第5.2节中,您通过字段List<Actor> actors为Film和Actor表定义了映射。使用JPAStreamer,您可以通过创建引用该字段的StreamConfiguration<Film>来实现Film和Actor表的连接,如下所示:
StreamConfiguration<Film> sc = StreamConfiguration.of(Film.class).joining(Film$.actors);
流配置现在替换了Film.class作为流源。在此过程中,我们可以添加另一个过滤器并翻转排序顺序。注意如何使用and/or运算符组合多个谓词。
public Stream<Film> actors(String startsWith, int minLength) { final StreamConfiguration<Film> sc = StreamConfiguration .of(Film.class).joining(Film$.actors); return jpaStreamer.stream(sc) .filter(Film$.title.startsWith(startsWith) .and(Film$.length.greaterThan(minLength))) .sorted(Film$.length.reversed());}作为对客户端的响应,似乎适合呈现电影的标题、电影的长度(以确认排序顺序是否正确)以及主演演员的列表:
@GET@Path("/actors/{startsWith}/{minLength}")@Produces(MediaType.TEXT_PLAIN)public String actors(String startsWith, short minLength) { return filmRepository.actors(startsWith, minLength) .map(f -> String.format("%s (%d min): %s", f.getTitle(), f.getLength(), f.getActors().stream() .map(a -> String.format("%s %s", a.getFirstName(), a.getLastName())) .collect(Collectors.joining(", ")))) .collect(Collectors.joining("\n"));}现在尝试使用起始字符A和最小长度为2小时调用新的端点:http://localhost:8080/actors/A/120。您应该期望以下结果:
ANALYZE HOOSIERS (181 min): TOM MCKELLEN, TOM MIRANDA, JESSICA BAILEY, GRETA MALDEN, ED GUINESSALLEY EVOLUTION (180 min): KARL BERRY, JUDE CRUISE, ALBERT JOHANSSON, GREGORY GOODING, JOHN SUVARI...ALAMO VIDEOTAPE (126 min): JOHNNY CAGE, SCARLETT DAMON, SEAN GUINESS, MICHAEL BENINGARIZONA BANG (121 min): KARL BERRY, RAY JOHANSSON, RUSSELL BACALL, GRETA KEITEL下面是生成的查询结果,确认联接已应用:
Hibernate: select f1_0.film_id, a1_0.film_id, ... from film f1_0 left join (film_actor a1_0 join actor a1_1 on a1_1.actor_id=a1_0.actor_id) on f1_0.film_id=a1_0.film_id where f1_0.title like replace(?,'\\','\\\\') and f1_0.length>? order by f1_0.length desc9.4 更新电影
虽然JPAStreamer的优势在于读取数据,但您也可以使用它来更新数据库。假设想象中的视频租赁店根据电影的长度制定价格模型。在这种情况下,您希望能够根据长度调整租赁费率。通过筛选出相关的电影并应用运算符forEach()来设置新的价格,可以轻松实现这一目标。通过使用@Transactional注释方法,可以确保Hibernate将更改持久化到Film实体中。
@Transactionalpublic void updateRentalRate(int minLength, int maxLength, BigDecimal rentalRate) { jpaStreamer.stream(Film.class) .filter(Film$.length.between(minLength, maxLength)) .forEach(f -> { f.setRentalRate(rentalRate); });}我让您自己创建一个便于客户启动租赁费率更新的端点。
10. 持续测试
您可以配置Quarkus在每次运行应用程序时自动触发执行Junit测试套件。或者,通过在Quarkus开发终端中按[r]手动触发执行。之前,我理解测试驱动开发(TDD)的价值,但我始终觉得它会妨碍专注于业务逻辑,因为我只会偶尔运行它们。这并不意味着Quarkus会为您编写测试,但是执行它们很容易,而且开发模式会不断提醒您这一点。
集成测试和单元测试都是如此。
尽管在本教程中最初概述了要求,但是在进行持续测试时还要注意一些特定事项。如果使用本教程中描述的Quarkus项目配置器,则应该已经设置好。否则,请确保您:
- 依赖于Quarkus JUnit 5模块
- 定义Maven Surefire插件版本(例如3.0.0),默认版本不支持JUnit 5
- (可选)使用Rest-assured进行简单的REST端点测试
要满足上述要求,请检查您的pom.xml中是否具有以下依赖项和插件配置:
<dependencies> <dependency> <groupId>io.quarkus</groupId> <artifactId>quarkus-junit5</artifactId> <scope>test</scope> </dependency> <dependency> <groupId>io.rest-assured</groupId> <artifactId>rest-assured</artifactId> <scope>test</scope> </dependency>…</dependencies>…<build> <plugins> <plugin> <artifactId>maven-surefire-plugin</artifactId> <version>3.0.0</version> <configuration> <systemPropertyVariables> <java.util.logging.manager> org.jboss.logmanager.LogManager </java.util.logging.manager> <maven.home>${maven.home}</maven.home> </systemPropertyVariables> </configuration> </plugin> …. </plugins></build>Quarkus测试文件放置在标准测试文件夹中,即/src/test/java(如果您的构建工具是Maven)。唯一的真正区别是您需要用@QuarkusTest注解您的测试类,以便Quarkus能够识别这些测试。下面的章节包含了如何编写单元测试和集成测试的示例。
10.1 单元测试
使用Quarkus创建单元测试与创建传统单元测试没有什么特别之处,唯一的区别是在开发模式下它们可以更快地执行。要测试FilmRepository,您只需将其注入到测试类中,就像FilmResource一样,然后调用CRUD方法。
下面是一个示例,确保您的getFilm()方法能够检索到标题为“AFRICAN EGG”的电影。
@QuarkusTestpublic class FilmRepositoryTest { @Inject FilmRepository filmRepository; @Test public void test() { final Optional<Film> film = filmRepository.getFilm(5); assertTrue(film.isPresent()); assertEquals("AFRICAN EGG", film.get().getTitle()); }}10.2 REST集成测试
Quarkus还可以轻松进行REST端点的集成测试。通过使用在前面章节中提到过的rest-assured库,您可以获得一个专门用于REST测试的丰富API。
下一个示例类似于之前的单元测试,但是以集成测试的形式呈现。在执行过程中,Quarkus会自动向您的电影端点发出一个ID为5的GET请求。该测试预期会得到一个成功的响应(HTTP状态码为200),并验证响应体是否包含电影的标题,“AFRICAN EGG”。
@QuarkusTestpublic class FilmResourceTest { @Test public void test() { given() .when().get("/film/5") .then() .statusCode(200) .body(containsString("AFRICAN EGG")); }}10.3 运行测试
假设您仍在Quarkus开发模式下运行,您可以使用以下其中一条命令来控制测试阶段:
[r] - 重新运行所有测试[f] - 重新运行失败的测试[v] - 打印上次测试运行的失败情况测试结果将记录在Quarkus日志中:
所有1个测试都通过(0个被跳过),共运行了1个测试,耗时336毫秒。测试完成于17:34:25,因为对的更改。
如果希望每次检测到应用程序变化时都执行这些测试,可以在application.properties中设置quarkus.test.continuous-testing=enabled。
您也可以选择在非开发模式下运行测试,使用以下命令:
mvn quarkus:test
11. 在Quarkus开发模式下运行调试器
经常情况下,测试可能会失败,却没有明显的原因,让我们感到困惑(或许也未必)。讽刺的是,有时我会把自己简单的错误归咎于外部库中的潜在错误。幸运的是,调试器为我们提供了帮助,揭示了问题出现的位置,并经常让我意识到自己的错误。
如果您希望在Quarkus开发模式下使用IntelliJ的调试器,您需要手动连接调试器。这个过程很简单,只需创建一个个性化的运行配置即可。转到Run > Edit Configurations并生成一个新的Remote JVM Debug配置。选择一个明确的标签,例如“Debug Quarkus”,以便能够轻松区分它与其他配置。由于Quarkus将端口5005用于调试会话,您只需指定要连接到的本地主机上的远程JVM,如下图所示。
</p
一旦配置完成,按照以下步骤以调试开发模式重新启动Quarkus:
./mvnw compile quarkus:dev -Ddebug
然后在IntelliJ中运行您的新调试Quarkus配置,连接到Quarkus进程,并像通常一样使用调试器。
12. 构建你的应用程序
尽管我们的应用程序在目前阶段可能功能有限,但它是完全可用且准备好提供用户访问与电影相关的信息。考虑到这一点,现在是准备部署的好时机。
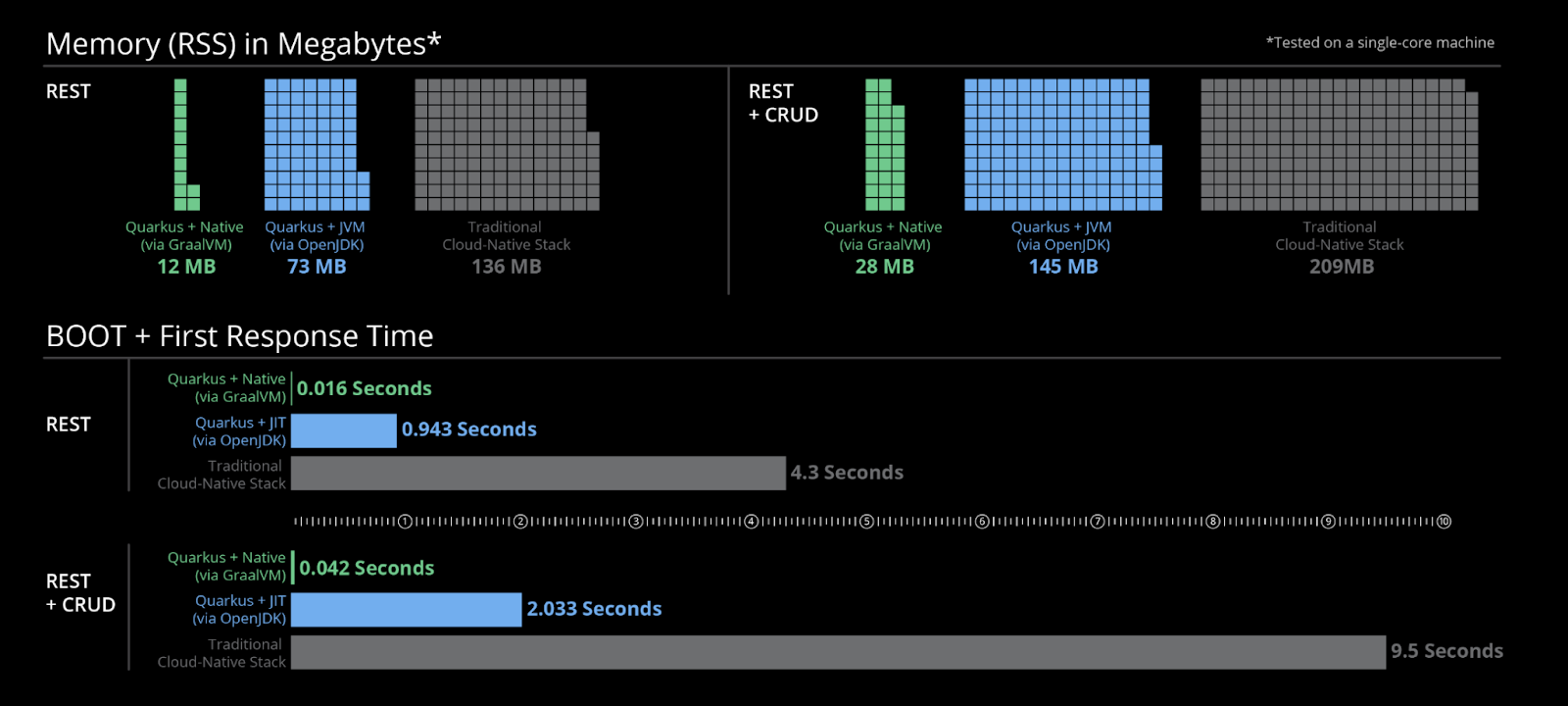
Quarkus提供了两种不同的构建选项:Quarkus JIT HotSpot编译器和由Graal VM提供动力的Quarkus本机构建。前者增强了标准Java JIT编译器以实现最佳性能,而后者则利用提前编译(AOT)来最大化构建时间的效率。虽然下面的图片是由Quarkus提供的营销资料,但我的实验结果证实了它所突出显示的实际性能提升。
12.1 通过OpenJDK进行Quarkus JIT构建
由于您已经在Quarkus平台上开发了项目,因此可以直接访问JIT编译器,无需任何额外步骤。上面的插图展示了Quarkus对标准编译器所做的重大改进,可能满足您的优化要求。
要启动标准的Quarkus构建过程,只需执行以下命令:
quarkus build
生成的构建结果存储在/target/quarkus-app中。然而,重要的是要注意生成的JAR文件并不是一个超级JAR文件,因此缺乏独立功能。为了成功部署,确保包含整个quarkus-app文件夹,以确保所有必要资源的可用性。
当您准备运行应用程序时,使用以下命令:
java -jar /target/quarkus-run.jar
注意Quarkus提示,指示应用程序启动所需的时间。作为参考,我启动这个应用程序的JIT编译版本大约需要1.7秒。
12.2 通过GraalVM进行Quarkus本机构建
现在,让我们深入Quarkus更有趣的方面——本机构建过程。尽管作为开发人员,你不需要额外的努力来进行本机编译,但需要一些耐心。与标准的JVM HotSpot构建相比,执行提前编译(AOT)需要的时间要更长。本机编译作为一种强大的压缩工具,最好用于准备部署软件的新版本。
由于Quarkus引入了使用GraalVM容器化变体进行本机构建的选项,我不会详细介绍GraalVM安装说明。要使用GraalVM Docker容器执行本机构建,请使用以下命令:
./mvnw package -Pnative -Dquarkus.native.container-build=true
或者,如果您本地已安装了GraalVM,则可以使用本地版本继续:
./mvnw package -Pnative
本机构建生成的可执行文件不是基于JVM的应用程序,而是特定于平台的本机应用程序。要运行它,只需执行位于目标文件夹根目录中的运行脚本(文件名对应您的应用程序的名称):
./target/quarkus-tutorial-1.0.0-SNAPSHOT-runner
再次注意Quarkus提示,观察启动本机版本所需的时间。在我的情况下,它只需要大约十分之一秒!
13. 资源
- Quarkus项目配置器
- Quarkus文档
- JPAStreamer文档
- 完整项目源代码










Leave a Reply