使用PyTorch预测森林火灾
在CPU上进行迁移学习是构建准确图像分类器的高效方式
在本文中,我使用PyTorch*的迁移学习来根据仅图像细节对空中照片进行火灾危险分类。MODIS火灾数据集记录了2018年至2020年加利福尼亚州的已知火灾。MODIS(中等分辨率成像光谱辐射计)数据集包含高分辨率图像和包含一定日期范围内的标记地图区域,以了解过去的山火位置。然后,我从之前的两年时间段(2016年至2017年)在已知未来火灾区域内和附近的地区中取样图像。使用预训练的ResNet 18模型(此模型以前未在空中照片上进行过训练),并补充了标记为“火灾”和“非火灾”的几百张图像来进行迁移学习。
对预训练模型(原始在ImageNet数据集上进行过训练)进行微调,以用于空中照片是从森林火灾预测的角度来提取有意义的信息的有效方法。ResNet架构以其深层和跳过连接,在各种计算机视觉任务中都表现出色,包括对象识别和图像分类。通过这种方法,我只需要几百张图像和大约15分钟的CPU时间就能构建一个准确的模型。继续阅读以获取更多细节!
使用空中图像的案例研究
我的方法是创建一个二分类器,仅通过2016年至2021年期间加利福尼亚州已知火灾和非火灾区域的空中图像进行预测。训练集是来自2016年至2017年的空中照片,即发生关键区域火灾之前的照片。评估集是从2018年至2020年(以及包括2021年的扩展集)在同一地点拍摄的图像。样本集中包含了燃烧和非燃烧区域。森林火灾的可能性基于通过MODIS数据集获取的已知森林火灾区域。所选区域位于萨克拉门托地区以及从海岸到内华达山脉的地区。该地区过去发生过许多大规模和致命的火灾。
数据获取
数据获取和预处理遵循以下基本步骤。首先,我使用Google Earth Engine*和JavaScript*程序收集MODIS火灾数据和空中照片。项目脚本可在ForestFirePrediction代码库中找到。接下来,我生成了一张地图,该地图基于美国农业部USDA/NAIP/DOQQ数据集。最后,我从NASA MODIS/006/MCD64A1数据集中获取了空中照片。
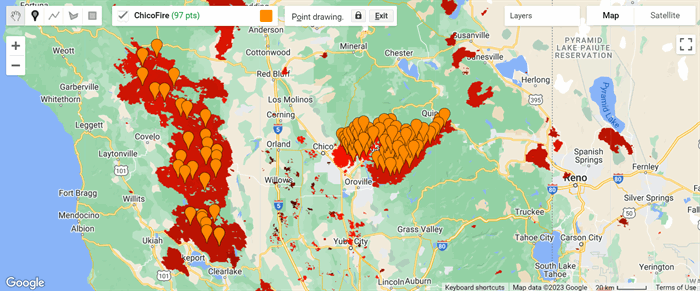
MODIS从2018年至2020年定义的火灾和非火灾位置在图1和图2中显示。红色区域是燃烧区域。橙色和青色的图钉表示用于图像的样本位置,其中青色表示无火样本点,橙色表示火灾样本点。每个图像覆盖约60平方英里的区域。
使用NAIP/DOQQ数据集来采样空中照片。例如,图3显示了加利福尼亚Paradise附近的一张空中图像,该地点在大火(2018年)之前。
我有106张火灾区域的样本图像和111张非火灾区域的样本图像(表1)。由于我使用迁移学习,所以我的数据集可以比从头开始训练模型时要小得多。训练、验证和测试图像的分布如下:
|
|
训练 |
验证 |
测试 |
|
火灾 |
87 |
9 |
10 |
|
非火灾 |
90 |
10 |
11 |
代码
该模型基于ResNet-18。我创建了四个主要的代码部分:实用函数,训练器类,模型类和指标类。此外,我还添加了用于显示最终混淆矩阵和模型准确度的代码。
导入
import intel_extension_for_pytorch as ipex import torch import torch.nn as nn import torchvision.models as models from torch.utils.data import DataLoader from torchvision import datasets, models, transforms
创建训练和验证数据集
下面,我们定义训练和验证图像的位置,并对每个集合中的每个图像进行图像增强。
num_physical_cores = psutil.cpu_count(logical=False)
data_dir = pathlib.Path("./data/output/")
TRAIN_DIR = data_dir / "train"
VALID_DIR = data_dir / "val"…
定义用于训练和验证集的数据集变换
下面,我们定义要对每个图像执行的一系列增强操作。
…img_transforms = {"train": transforms.Compose([transforms.RandomHorizontalFlip(), transforms.RandomVerticalFlip(), transforms.RandomRotation(45), transforms.ToTensor(), transforms.Normalize(*imagenet_stats),),…}…
定义模型类
我们的模型是基于ResNet18的深度神经网络二分类器。
class FireFinder(nn.Module):… def __init__(self, backbone=18, simple=True, dropout=.4): super(FireFinder, self).__init__() backbones = { 18: models.resnet18, } fc = nn.Sequential( nn.Linear(self.network.fc.in_features, 256), nn.ReLU(), nn.Dropout(dropout), nn.Linear(256, 2)
定义训练器类
这一步中使用了Intel® Extension for PyTorch*。它是Intel® AI Analytics Toolkit的一部分。
class Trainer:… self.loss_fn = torch.nn.CrossEntropyLoss() self.ipx = ipx self.epochs = epochs if isinstance(optimizer, torch.optim.Adam): self.lr = 2e-3 self.optimizer = optimizer(self.model.parameters(), lr=lr) def train(self): self.model.train() t_epoch_loss, t_epoch_acc = 0.0, 0.0 start = time.time() for inputs, labels in tqdm(train_dataloader, desc="tr loop"): inputs, labels = inputs.to(self.device), labels.to(self.device) if self.ipx: inputs = inputs.to(memory_format=torch.channels_last) self.optimizer.zero_grad() loss, acc = self.forward_pass(inputs, labels) loss.backward() self.optimizer.step() t_epoch_loss += loss.item() t_epoch_acc += acc.item() return (t_epoch_loss, t_epoch_acc)… def _to_ipx(self): self.model.train() self.model = self.model.to(memory_format=torch.channels_last) self.model, self.optimizer = ipex.optimize(self.model, optimizer=self.optimizer, dtype=torch.float32)
训练模型
我们使用dropout为0.33和学习率为0.02训练模型20个时期:
epochs = 20 ipx = True dropout = 0.33 lr = 0.02 torch.set_num_threads(num_physical_cores) os.environ["KMP_AFFINITY"] = "granularity=fine,compact,1,0" start = time.time() model = FireFinder(simple=simple, dropout=dropout) trainer = Trainer(model, lr=lr, epochs=epochs, ipx=ipx) tft = trainer.fine_tune(train_dataloader, valid_dataloader)
模型推理
我定义了用于对我们的模型进行推理的类和函数。
class ImageFolderWithPaths(datasets.ImageFolder):…def infer(model, data_path: str): transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize(*imagenet_stats)]) data = ImageFolderWithPaths(data_path, transform=transform) dataloader = DataLoader(data, batch_size=4)…
下面的示例代码演示了如何使用模型对图像进行评分。
images, yhats, img_paths = infer(model, data_path="./data//test/")
模型准确性
下面的混淆矩阵显示该模型的整体准确度约为89.9%,在21个样本中有两个假阴性。
图4显示了所有样本(训练、验证和测试)的模型预测情况。空间覆盖图显示该模型在预测火灾和非火灾危险的面积时表现良好。绿色图钉表示模型预测为非火灾的位置,红色图钉表示模型预测为火灾发生的样本。红色多边形区域是2018年到2020年的真实火灾区域。
图5放大显示了加利福尼亚州天堂附近的地图。
结论
我使用PyTorch提供的图像分析能力和底层的Intel优化来训练和测试了一个ResNet18模型,以展示准确的森林火灾预测。该模型可以接受覆盖60平方英里区域的航拍照片,并做出准确的火灾和非火灾预测。目前模型的准确度约为89%,但通过更多的迭代、更多的图片和更多的正则化注意力可以进一步提高准确度。
通过点击邀请链接,加入我们在Intel® DevHub Discord上进行进一步讨论。此外,还可以参考新的Intel® Developer Cloud,在最新的Intel®硬件上尝试Intel AI Analytics Toolkit。









Leave a Reply