如何在您的应用程序中处理多语言姓名
今年早些时候,我和我的团队在工作中观察我们一个注册API中发生的错误我们看到近5%的请求失败,都是因为400错误而根本原因追溯到一个正则表达式
今年早些时候,我在工作中与我的团队一起研究了我们的一个注册API中发生的错误。我们发现近5%的请求失败,全部是因为400 BAD REQUEST错误。而其根本原因被追溯到了一个正则表达式检查。
这个正则表达式是一个限制条件,我们的系统只允许人们使用英文字符来输入他们的名字和姓氏。问题是,许多人选择用他们的母语输入名字。
这些客户是有兴趣从我们的平台购买健康保险的人,他们是我们用户群体中非常重要的一部分。
为了解决这个问题,我们决定让这5%的用户能够以他们偏爱的任何语言输入他们的名字。但这带来了很多需要解决的挑战-我将在这里解释我们是如何解决这些问题的。
处理多语言名字的挑战
1. 数据存储策略
我们依赖MongoDB来存储和检索用户的名字。虽然MongoDB允许存储所有UTF-8兼容的字符,但在处理搜索时会遇到问题。
对于英文名字,我们的搜索操作使用简单的排序法。相应的字段被适当地索引以优化查询性能。
尽管MongoDB也支持为其他语言实现排序索引,但这意味着您必须通知数据库您打算搜索的特定语言。问题在于我们的用户群体涵盖了许多语言,仅印度就拥有20多种不同的语言。
我们的目标是至少支持所有印度语言。但这意味着为每种支持的语言实现排序索引将导致索引数量的增加,并且随着时间的推移也会增加索引大小。
这种方法还会让开发人员需要记住为每种新语言添加索引,这远非是一个高效的解决方案。
2. API网关限制
我们所有的API都是在一个API网关后面开放的。在网关转发请求到相应的API服务之前,一个入站策略会验证用户的身份认证状态。一旦用户经过身份认证,它会获取基本的用户信息,如姓名、手机号码和其他元数据,并将其附加到该API的请求头中。
许多API依赖于这些针对特定用户的头部数据进行进一步处理。
但是网关有一个限制-它只允许使用ASCII字符进行处理和包含在头部中。所以我们必须确保即使名字可能是其他语言,我们共享的响应必须完全是英文。
此外,这个过程需要保持快速,因为身份认证的任何延迟都可能导致API性能变差。
3. 外部合作伙伴对方言名字的挑战
即使我们开始接受多种语言的名字,我们的合作伙伴也必须接受来自我们的这些名字。如果他们不支持多语言名字,那么用户的使用体验就会被破坏。
一个例子就是我们的支付合作伙伴。我们必须确保我们的支付团队始终获得英文名字,即使用户输入了其他语言的名字。
此外,我们希望尽可能避免在可以的情况下弹出提示框提示用户以英文输入名字。所以在考虑到这些问题的同时,我们必须构建一个可行的解决方案。
我们是如何解决这些挑战的
虽然使用第三方转换服务可能是最简单的方法,但出于成本控制和完全控制的考虑,我们选择了开发一个内部解决方案。
考虑到API网关和支付合作伙伴的要求,我们明确需要将非英语名字转换为对应的英语名字。但是将这个英语名字呈现给用户是违背直觉的-例如使用印地语输入一个名字,然后登录后看到它被转换为英语是矛盾的。
为了解决这个问题,我们开发了一种双命名策略。原来的字段"firstName"和"lastName"将保留用户输入的名字和姓氏的原始语言。然后我们引入了两个额外的字段"englishFirstName"和"englishLastName",专门用于存储这些名字的英语对应名字。这些英语名字可以与API网关和我们的支付合作伙伴共享。
在解决这些名字的高效存储的挑战方面,我们预计随着所支持的语言数量的增长,管理排序索引将变得难以操作。搜索也将需要为每个查询指定排序规则,增加了一层复杂性。因此,我们决定转变策略。
我们的第二种方法是使用 Unicode。由于我们的目标是支持多种语言而没有约束条件,我们意识到 Unicode 能够有效地表示几乎所有语言的字符。因此,我们决定在各自的 MongoDB 字段中存储名字的 Unicode 表示。
我们只是在数据库和应用程序之间添加了另一个层次。它在从数据库检索名字并将本地名字转换为相应的英文名字时,将这些 Unicode 字符串转换为本地语言中的原始值。然后,在任何插入或更新操作时,它会将它们存储在 englishFirstName 和 englishLastName 中。
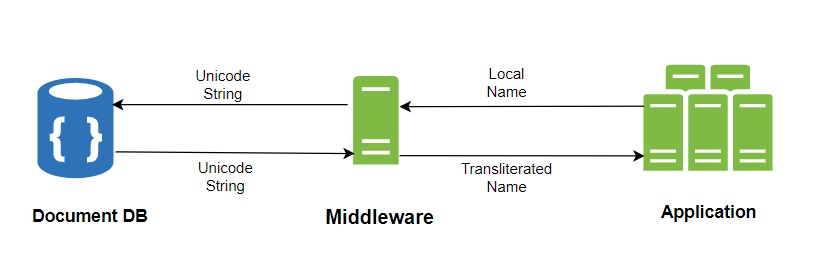
这种策略为我们提供了无缝管理多语言名称的灵活性。
关键设计考虑因素
1. Unicode 优化
Unicode 表示通常由一个 6 个字符的字符串组成,其中 ‘a’ 表示为 ‘U+0061’,’P’ 表示为 ‘U+0050’,通常以 ‘U+00’ 开头。为了节省数据库存储空间,我们选择省略 ‘U+’ 前缀和前导零,优化我们的数据存储。
2. 音译 vs. 翻译
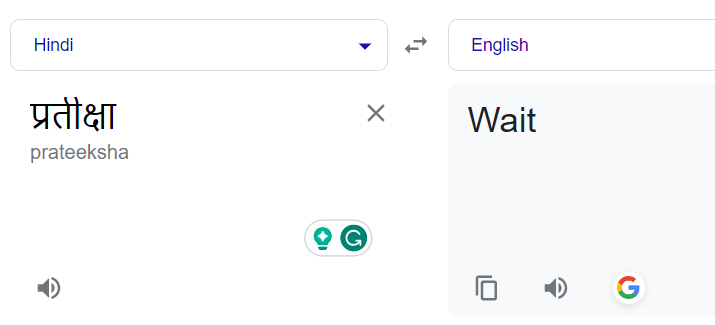
最初,我们的目标是音译,它需要将名字从一种文字转换为另一种文字,并保留其语音音节。例如,印地语单词 "प्रतीक्षा" 应该转换为 "Partiksha",而不是翻译成它的英文等效词 "Wait"。
但我们意识到 Google 翻译主要专注于翻译而不是音译。同样,在我们的第一次迭代中,我们不想直接使用付费的 Google 音译服务,因此我们使用了 Google 翻译的免费版本开发了自己的音译服务。
3. 上下文增强
我们的另一个关键观察结果是为 Google 翻译 API 提供上下文信息会影响其响应。
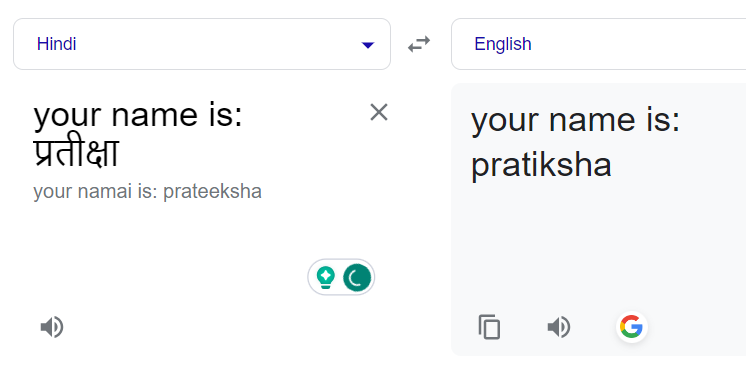
为了利用这一点,我们尝试向非英语名字添加陈述前缀以建立上下文。经过几次试验后,我们发现对于较短的名字(小于 5 个字符),更长的前缀陈述并没有产生理想的结果,Google 通常返回相同的印地语词。对于较长的名字,我们使用了更长的陈述,并通过试验和错误确定了最佳的平衡点。
正常情况下,翻译名字会导致其字面翻译。例如,”प्रतीक्षा” 翻译为 “Wait” 而不是 “Pratiksha”:
添加前缀陈述可以纠正这个问题:
好了,现在让我们看看我们实际如何实现所有这些。
初始代码
在我们的第一次迭代之后,我们开发了下面的代码进行音译。在这里,我们使用的是 @iamtraction/google-translate 库,它是在免费的 Google 翻译 API 上编写的包装器。
const translate = require('@iamtraction/google-translate');function getGoogleTranslateText(localName) { /* 添加一个英文句子在名字之前,以便它不会被翻译为其字面意思。 例如,将 परीक्षा 转换为 Exam 而不是 Pariksha。 */ if (localName.length <= 5) { return `name: ${localName}`; } return `your name is: ${localName}`;}async function translateNameToEnglish(localName) { if (localName.match(/^[a-zA-Z ]+$/i)) { // 如果名字已经是英文,直接返回 return localName; } try { const res = await translate(getGoogleTranslateText(localName), { to: 'en', }); const translatedName = res.text.split(':')[1].trim(); return translatedName; } catch (err) {} // 如果出错,返回 Unicode 字符串 return localName;}测试版发布和生产挑战
一旦我们构建完成,我们就将这个功能发布为测试版,并在最初的几天内有大约250名用户注册了非英文名字。
通过简单地观察一些翻译文本,我们发现将名称从本地语言转换为Unicode的过程完全正常,用户能够以他们偏好的语言在应用程序中正确地查看他们的名称。
尽管如此,我们在英文音译的过程中还是发现了两个问题:
- 有些名字音译错误。这可能是因为我们依赖于 Google 翻译这个通用的翻译服务,而不是专门的音译服务。
- 有些名字保持不变,没有进行音译。这些名字以与原始语言相同的语言返回。这意味着在翻译之前通过添加前缀句子来提供上下文对特定的名字造成了问题。
这促使我们进一步调查,发现了一个名为 “unidecode” 的 npm 包,它可以将 Unicode 转换为原始字符串。尽管与 unidecode 的初始测试显示准确性,但也显示出了轻微的拼写差异。相比之下,谷歌始终提供正确拼写的翻译。我们只需要找到一个同时使用两者优点的方法。
所以我们将 unidecode 作为解决方案的一部分,并将其纳入我们的算法中。
改进的解决方案
这是我们想出的解决方案:
const translate = require('@iamtraction/google-translate');const unidecode = require('unidecode');const { isAlmostEqualStrings } = require('./levenshtein');/** * * @param {String} localName * @description 基于 localName 的长度为 Google 生成文本(用于短名字的语境更简短的陈述) * @returns {String} 返回要翻译的文本 */function getGoogleTranslateText(localName) { /* 在名字之前添加一个英文句子,以免其被翻译成字面意思。 例如,将“परीक्षा”翻译为“Exam”而不是“Pariksha”。 */ if (localName.length <= 5) { return `name: ${localName}`; } return `your name is: ${localName}`;}/** * * @param {String} localName * @description 返回几乎音译的名字 * @returns {String} 返回从本地语言转换过的音译名字 */function transliterate(localName, googleTranslatedName) { const decodedName = unidecode(localName); if ( decodedName && Array.from(decodedName)[0]?.toLowerCase() !== Array.from(googleTranslatedName)[0]?.toLowerCase() && !isAlmostEqualStrings(decodedName, googleTranslatedName) ) { return decodedName; } return googleTranslatedName;}/** * * @param {String} Input non English string * @description 将非英文字符串翻译为英文 * @returns {String} 返回翻译后的字符串 */async function translateNameToEnglish(localName) { if (!localName || localName.match(/^[a-zA-Z ]+$/i)) { // 如果名字已经是英文,则直接返回 return localName; } try { const res = await translate(getGoogleTranslateText(localName), { to: 'en', }); const translatedName = res.text.split(':')[1].trim(); return transliterate(localName, translatedName); } catch (err) {} // 出错时,返回原始字符串 return localName;}在获取翻译后的名字之后,我们将其输入最近引入的 transliterate 函数中。在这个函数中,我们的初始步骤是使用 Unidecode 库提取解码后的字符串。但问题的关键是:我们如何确定要优先考虑哪个结果——解码后的字符串还是翻译后的字符串?
为了解决这个问题,我们实施了 Levenshtein Distance,这是一种计算两个字符串之间相似度的算法。
起初,我们检查解码后的名字的第一个字符是否与翻译后的名字的第一个字符相匹配。如果不匹配,那么可以确定翻译后的名字是错误的,因此我们返回解码后的名字,即使它可能包含轻微的拼写差异,也比错误的翻译更好。
如果匹配,则进行 Levenshtein Distance 算法。
Levenshtein 距离是一个数字,告诉你两个字符串有多相似。数字越高,两个字符串越不相似。
在这个实现中,我们有一个名为 isAlmostEqualStrings 的函数,它生成一个从0到1的值,并且如果该值超过一定阈值则返回 true。在我们的情况下,我们将阈值设为0.8。
如果Levenshtein距离表明匹配率超过80%,我们返回翻译后的名称。否则,我们返回解码后的名称。这种方法确保我们优先考虑准确性,根据已确定的相似性阈值提供可靠的结果。
这个更新后的算法大大减少了上述提到的问题。尽管它不是100%准确,但非常好地解决了我们5%的情况。
结论
我们开发的算法完全是内部的,没有产生任何费用。虽然投资于付费解决方案可能会提供更好的结果,但明智的工程决策和一些聪明的技巧在降低成本和有效解决我们具体问题方面起到了至关重要的作用。
上述实施的全部代码以及Levenshtein Distance算法可以在GitHub上找到(欢迎贡献/更正)。
有关此事,我们的文章到此结束。如果您想进一步讨论任何技术主题,或者如果您有任何问题、建议或一般性反馈,请随时与我联系:
愉快学习!








Leave a Reply