如何在登录后爬取亚马逊产品评价
如何在登录后批量获取亚马逊产品评论
亚马逊是最受网络爬虫欢迎的电子商务网站,每月被抓取的产品页面数量以十亿计。
它还拥有庞大的产品评论数据库,对于市场研究和竞争对手监测非常有用。
您可以从亚马逊网站提取相关数据,并以电子表格或JSON格式保存。甚至可以自动化这个过程以定期更新数据。
抓取亚马逊产品评论并不总是一件简单的事情,特别是在需要登录时。在本指南中,您将学习如何在登录后抓取亚马逊产品评论。您将学习登录过程、解析评论数据以及将评论导出为CSV的过程。
没有废话,让我们开始吧。
先决条件和项目设置
我们将使用Node.js的Puppeteer库来抓取亚马逊评论。请确保已在您的系统上安装了Node.js。如果尚未安装,请访问官方Node.js网站并进行安装。
安装Node.js后,安装Puppeteer。Puppeteer是一个为自动化任务和与动态网页交互提供高级用户友好API的Node.js库。
现在,让我们安装和配置Puppeteer。
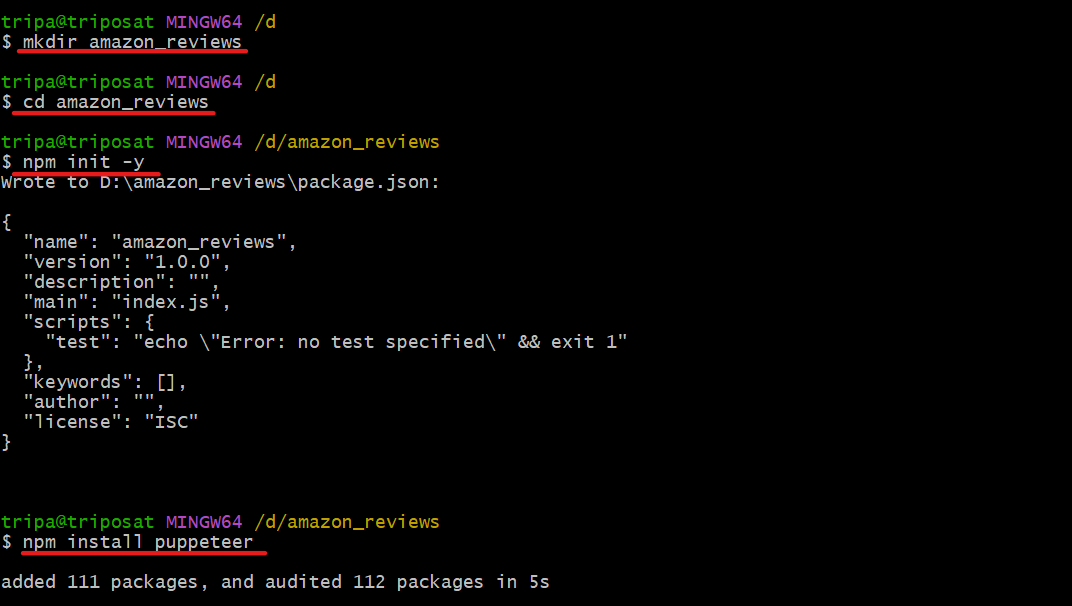
打开终端并创建一个任意名称的新文件夹。(在我的例子中,是amazon_reviews)。
mkdir amazon_reviews将当前目录更改为上面创建的文件夹。
cd amazon_reviews很好,您现在在正确的目录中。执行以下命令以初始化package.json文件:
npm init -y最后,使用以下命令安装Puppeteer:
npm install puppeteer过程如下图所示:
现在,在任何代码编辑器中打开该文件夹,并创建一个新的JavaScript文件(index.js)。确保层次结构如下所示:
所有设置完成。现在我们准备好编写爬虫程序了。
注意:请确保您在亚马逊上有一个账户,以便能够进行本教程的其余步骤。
第一步:访问公共页面
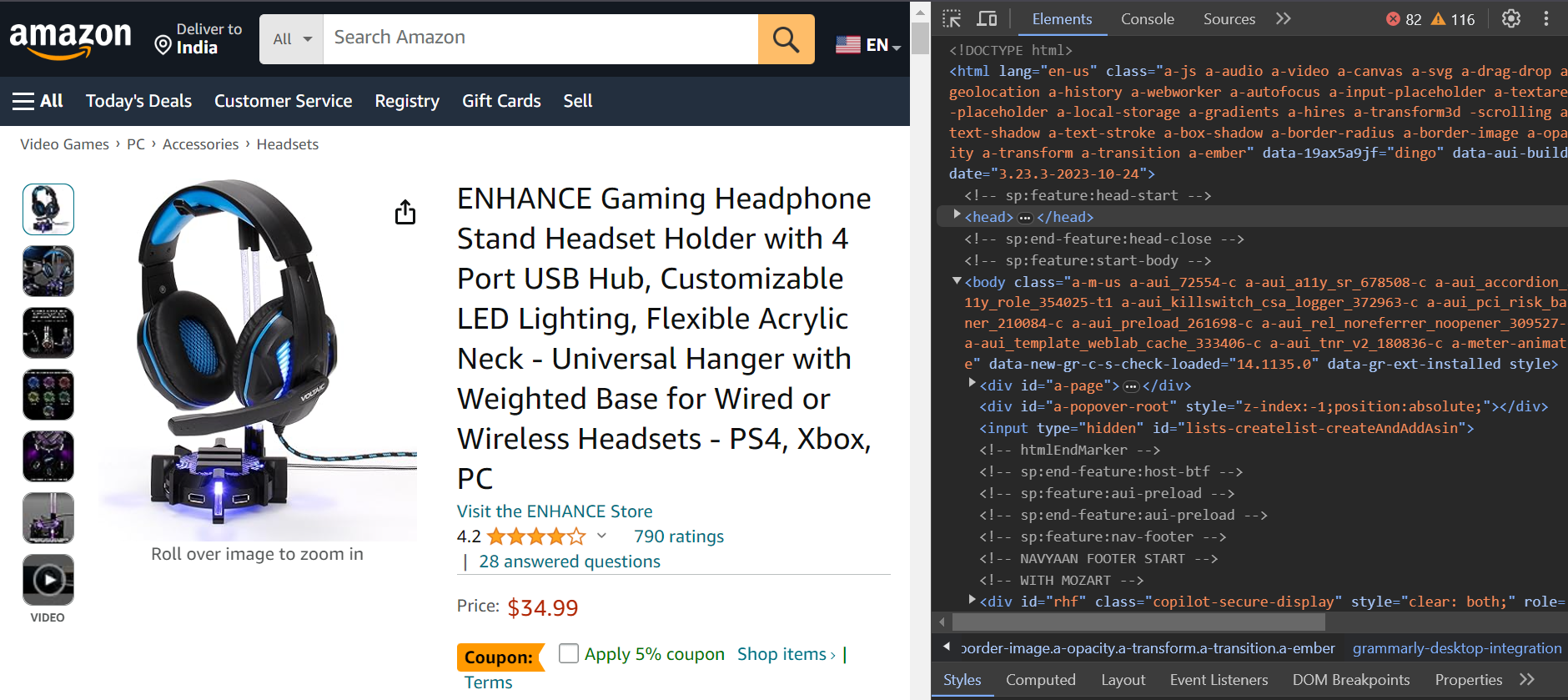
您将要抓取下面所示产品的评论。您将提取作者的姓名、评论标题和日期。
以下是产品的URL:https://www.amazon.com/ENHANCE-Headphone-Customizable-Lighting-Flexible/dp/B07DR59JLP/
首先,您将登录亚马逊,然后重定向到产品URL以抓取评论。
第二步:抓取登录后的页面
亚马逊的多阶段登录过程要求用户输入用户名或电子邮件,点击“继续”按钮输入密码,最后提交。用户名和密码字段通常位于不同的页面上。
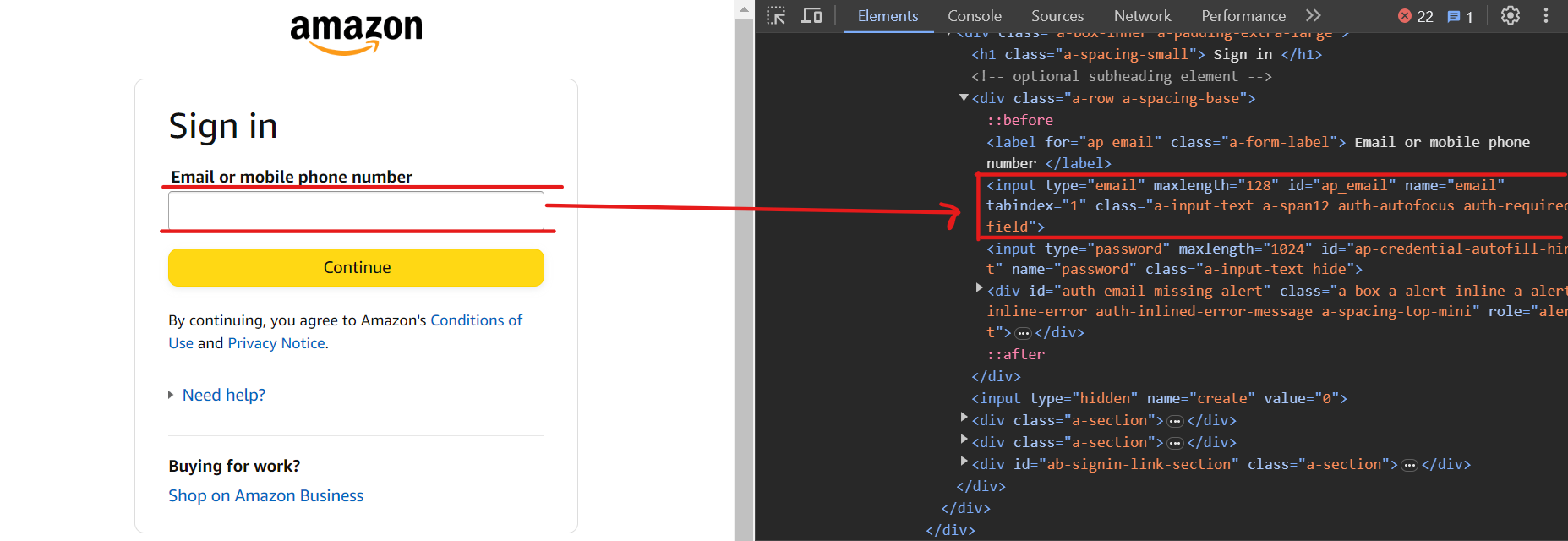
使用选择器input[name=email]输入电子邮件。
现在,使用选择器input[id=continue]点击“继续”按钮。
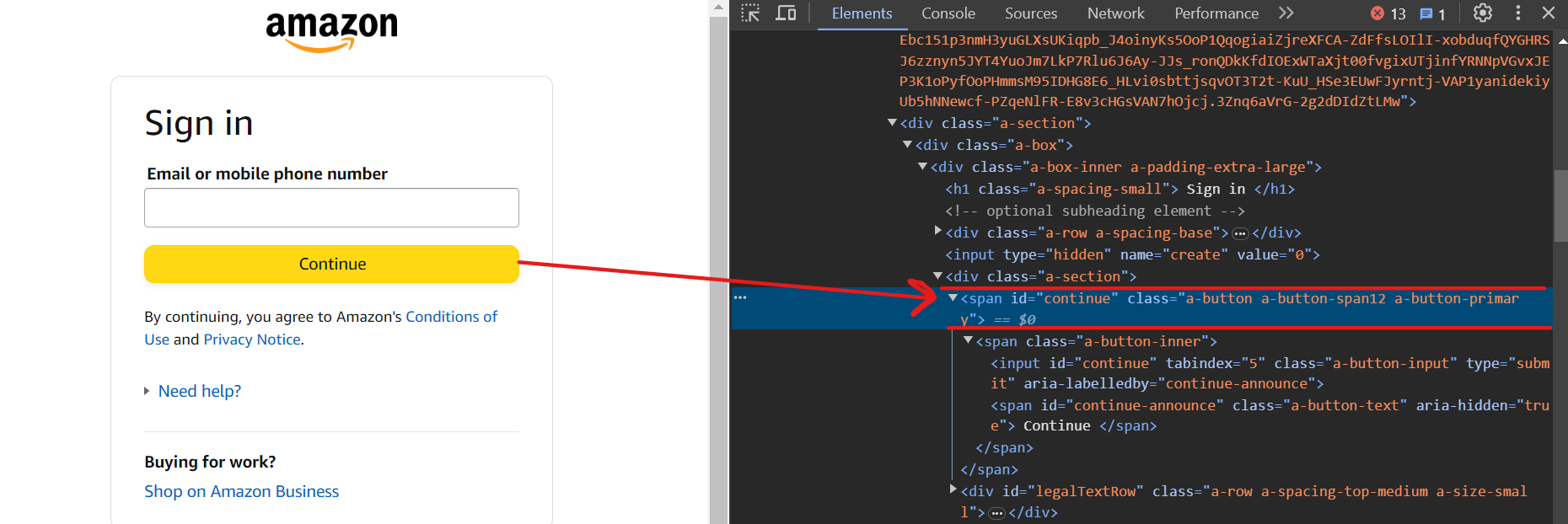
现在你应该在下一页上。要输入密码,请使用选择器input[name=password]。
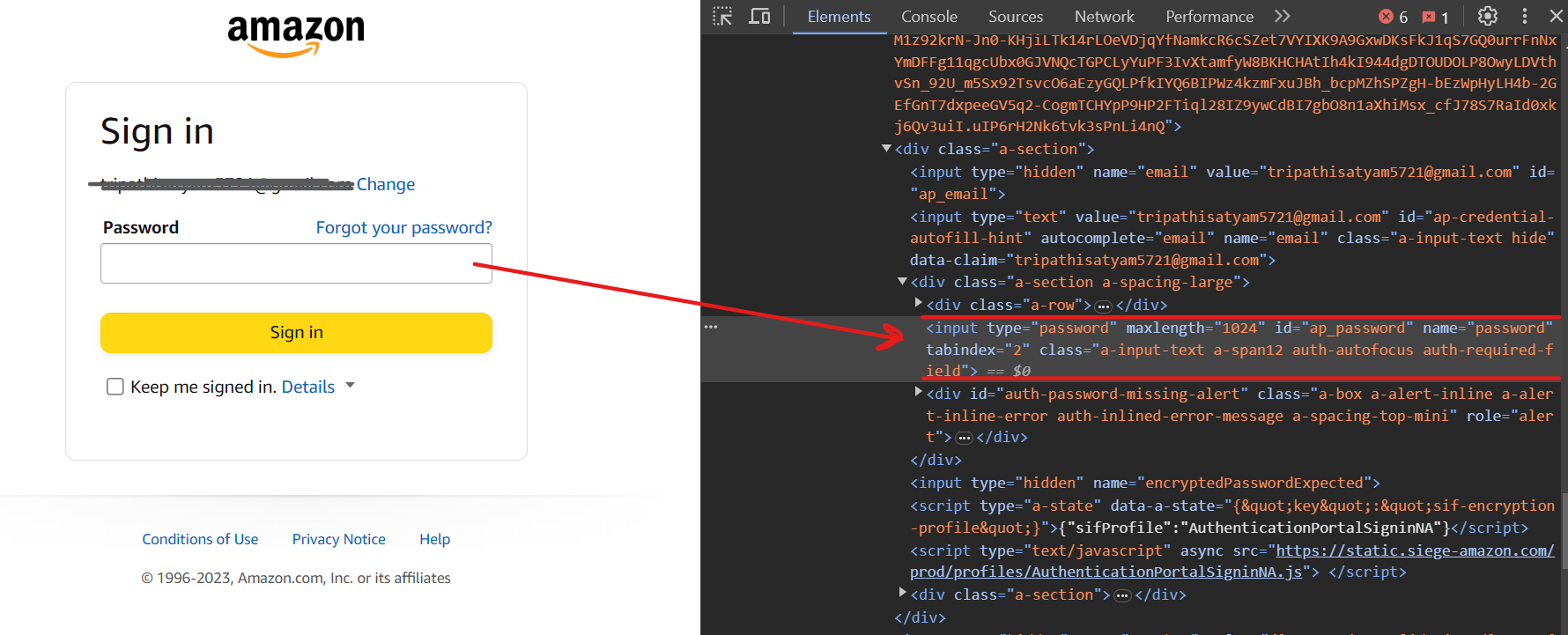
最后,使用选择器input[id=signInSubmit]点击“登录”按钮。
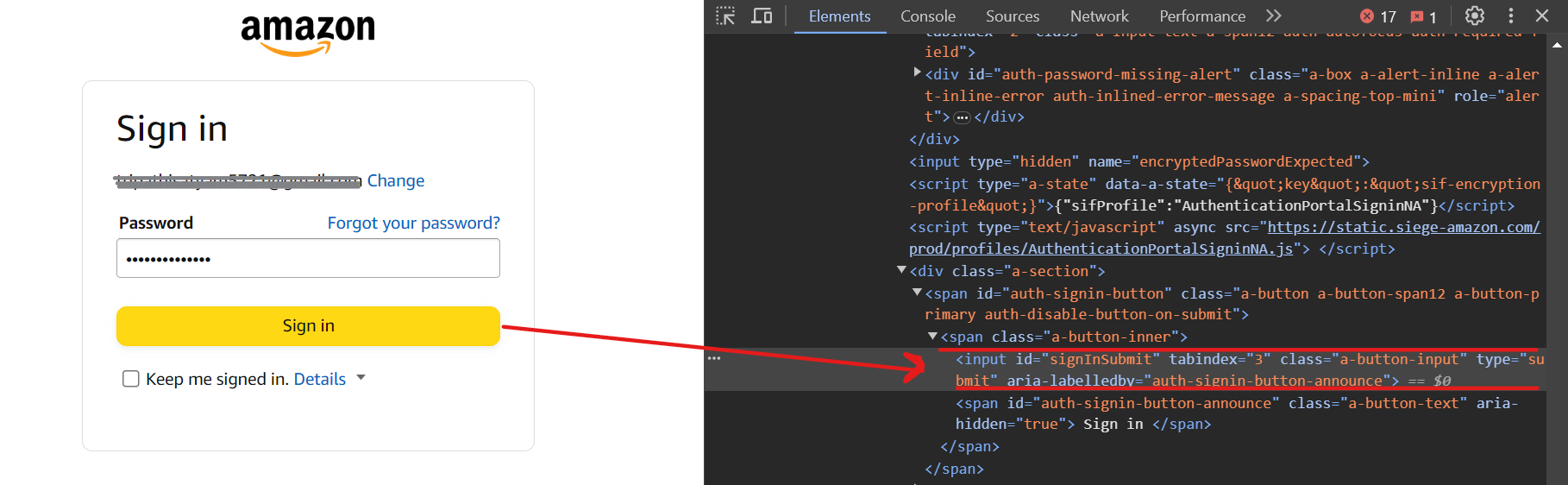
这是登录过程的代码:
const selectors = { emailid: 'input[name=email]', password: 'input[name=password]', continue: 'input[id=continue]', singin: 'input[id=signInSubmit]',}; await page.goto(signinURL); await page.waitForSelector(selectors.emailid); await page.type(selectors.emailid, "[email protected]", { delay: 100 }); await page.click(selectors.continue); await page.waitForSelector(selectors.password); await page.type(selectors.password, "mypassword", { delay: 100 }); await page.click(selectors.singin); await page.waitForNavigation();我们按照上面讨论的相同步骤进行操作。首先,进入登录URL,输入电子邮件ID,然后点击“继续”按钮。然后输入密码,点击“登录”按钮,等待一会儿完成登录过程。
登录过程完成后,您将被重定向到产品页面以抓取评论。
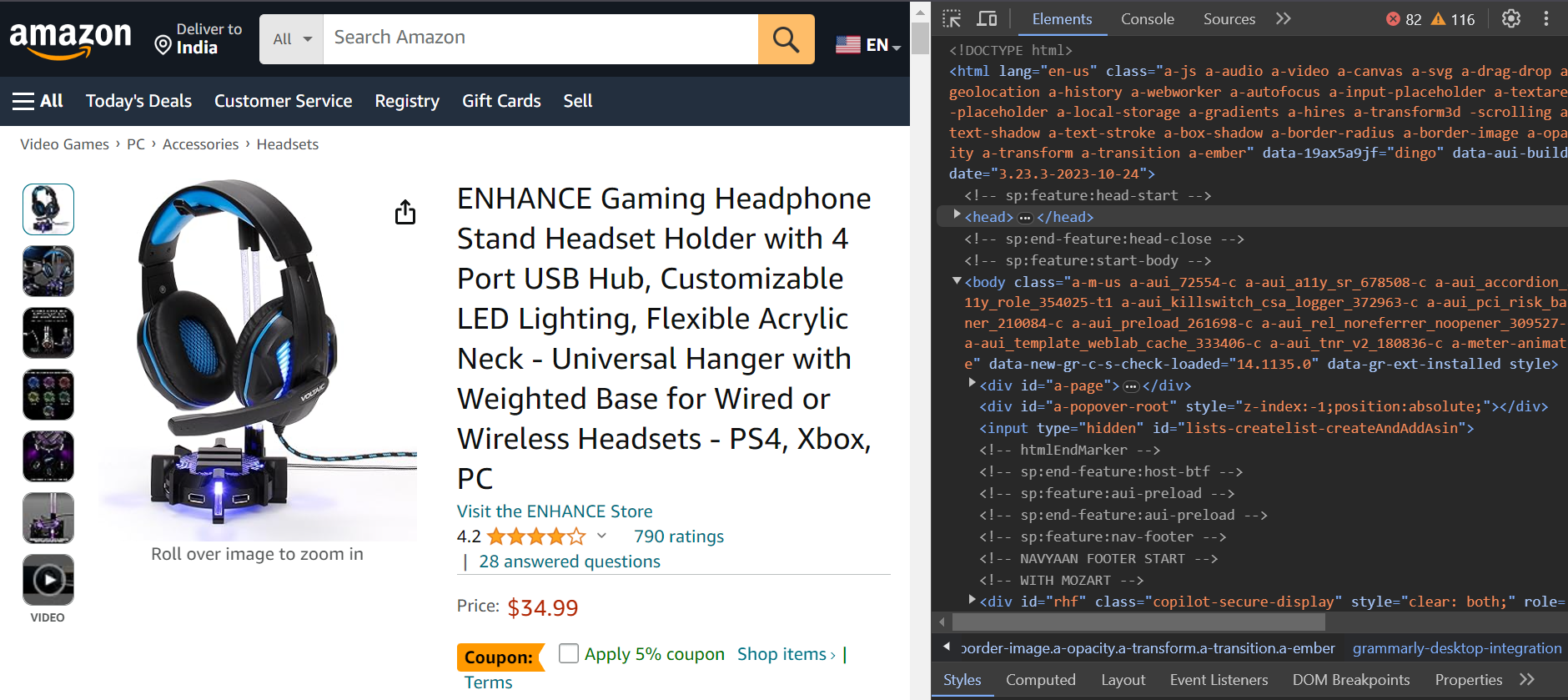
步骤3:解析评论数据
您已成功登录,并且现在处于要抓取的产品页面上。现在让我们解析评论数据。
在页面上,您将找到各种评论。这些评论包含在具有ID cm-cr-dp-review-list的父级div中,该父级div包含当前页面上的所有评论。如果您想要访问更多评论,您需要使用分页过程导航到下一页。
此父级div有多个子级div,每个子级div包含一个评论。要提取评论,您可以使用选择器#cm-cr-dp-review-list div.review。
const selectors = { allReviews: '#cm-cr-dp-review-list div.review', authorName: 'div[data-hook="genome-widget"] span.a-profile-name', reviewTitle: '[data-hook=review-title]>span:not([class])', reviewDate: 'span[data-hook=review-date]',};此选择器表示您首先转到具有ID cm-cr-dp-review-list的元素,然后搜索具有数据钩子review的所有div元素。
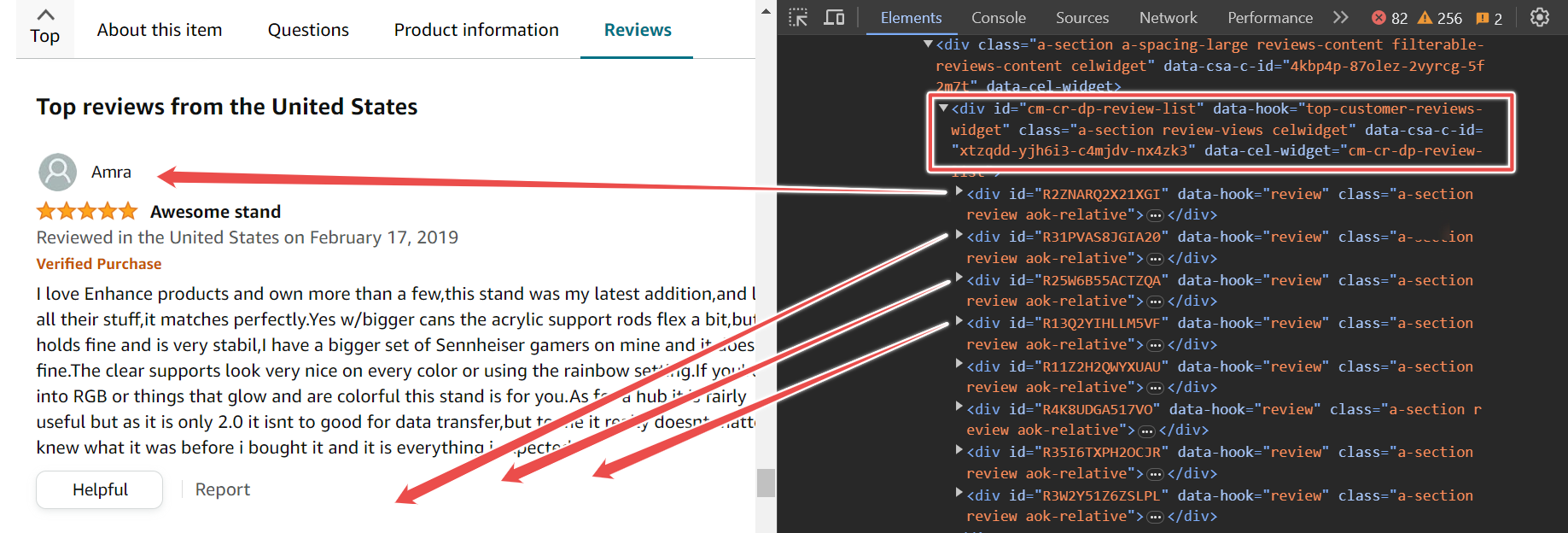
下面的代码片段显示您应该首先转到产品URL,等待选择器加载,然后抓取所有评论并将其存储在reviewElements变量中。
await page.goto(productURL);await page.waitForSelector(selectors.allReviews);const reviewElements = await page.$$(selectors.allReviews);现在,让我们提取作者的姓名、评论标题和日期。
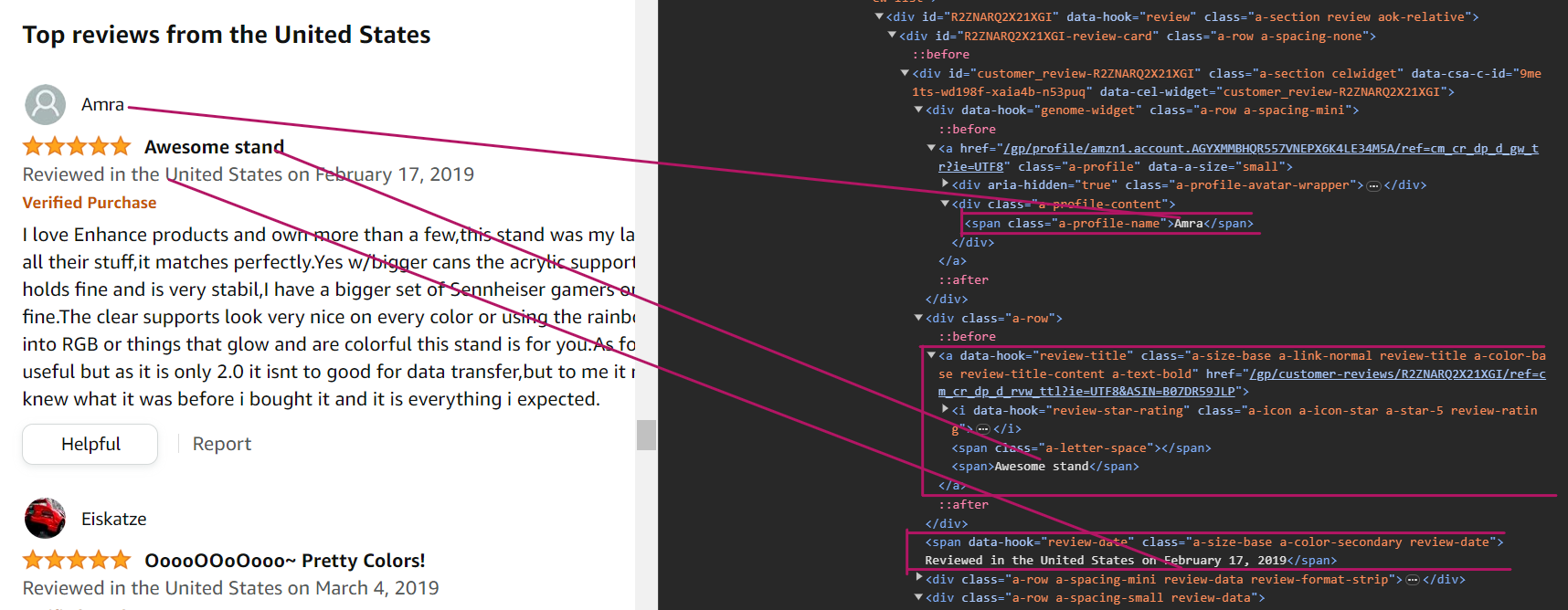
要解析作者名字,您可以使用选择器 div[data-hook="genome-widget"] span.a-profile-name。此选择器告诉我们首先搜索带有 data-hook 属性设置为 genome-widget 的 div 元素,因为名字就在这个 div 元素内。然后搜索带有 class 名称为 a-profile-name 的 span 元素。这个元素包含了作者的名字。
const author = await reviewElement.$eval(selectors.authorName, (element) => element.textContent);要解析评论标题,您可以使用 CSS 选择器 [data-hook="review-title"] > span:not([class])。此选择器告诉我们搜索 span 元素,它是 [data-hook="review-title"] 元素的直接子元素,并且没有 class 属性。
const title = await reviewElement.$eval(selectors.reviewTitle, (element) => element.textContent);要解析日期,您可以使用 CSS 选择器 span[data-hook="review-date"]。此选择器告诉我们搜索 span 元素,它具有 data-hook 属性设置为 review-date。这个元素包含了评论日期。
const rawReviewDate = await reviewElement.$eval(selectors.reviewDate, (element) => element.textContent);请注意,您将获取整个文本,包括位置,而不仅仅是完整日期。因此,您必须使用正则表达式模式从文本中提取日期。
之后,将所有数据合并到 reviewData 中,然后将其推入最终列表 reviewsData。
const datePattern = /(\w+\s\d{1,2},\s\d{4})/; const match = rawReviewDate.match(datePattern); const reviewDate = match ? match[0].replace(',', '') : "Date not found"; const reviewData = { author, title, reviewDate, }; reviewsData.push(reviewData); }以上过程将运行直到解析当前页面上的所有评论。以下是解析数据的代码片段:
for (const reviewElement of reviewElements) { const author = await reviewElement.$eval(selectors.authorName, (element) => element.textContent); const title = await reviewElement.$eval(selectors.reviewTitle, (element) => element.textContent); const rawReviewDate = await reviewElement.$eval(selectors.reviewDate, (element) => element.textContent); const datePattern = /(\w+\s\d{1,2},\s\d{4})/; const match = rawReviewDate.match(datePattern); const reviewDate = match ? match[0].replace(',', '') : "Date not found"; const reviewData = { author, title, reviewDate, }; reviewsData.push(reviewData); }太棒了!您已成功解析了所需的数据,现在以 JSON 格式显示如下:
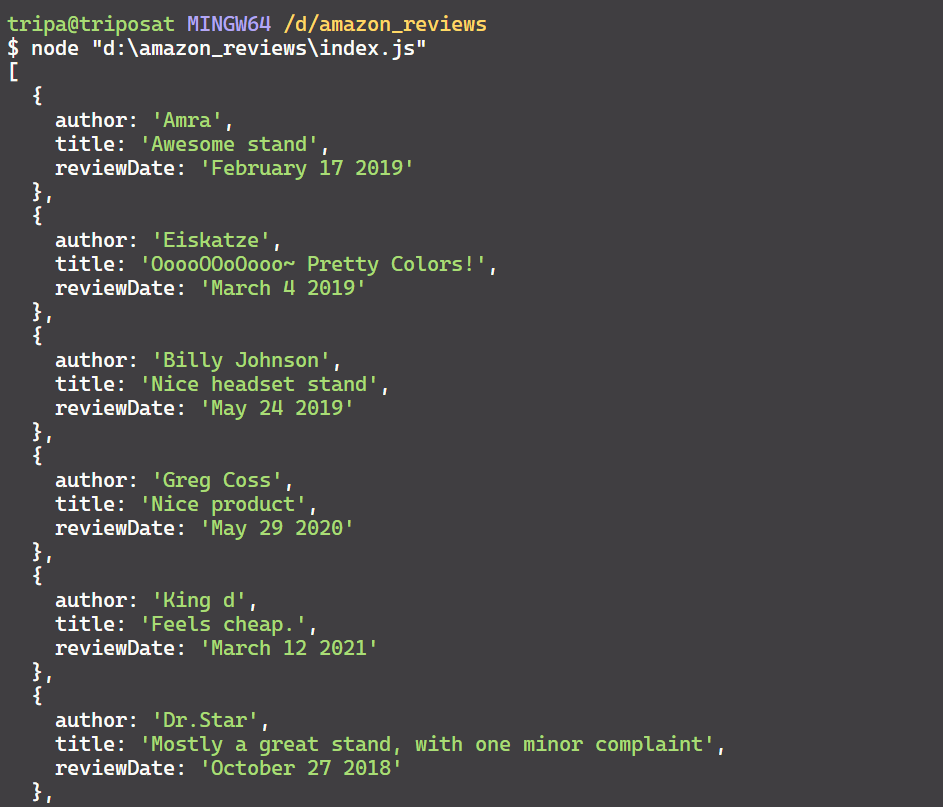
步骤 4:将评论导出为 CSV
您已将评论解析为 JSON 格式,这种格式稍微容易读懂。为了使数据更易读和更适合其他用途,您可以将这些数据转换为 CSV 格式。
有很多方法可以将 JSON 数据转换为 CSV,但我们将使用简单有效的方法。以下是将 JSON 转换为 CSV 的简单代码片段:
let csvContent = "Author,Title,Date\nfor (const review of reviewsData) { const { author, title, reviewDate } = review; csvContent += `${author},"${title}",${reviewDate}\n`; }const csvFileName = "amazon_reviews.csv";await fs.writeFileSync(csvFileName, csvContent, "utf8");以下是 CSV 文件的输出结果。

到这里,你就做到了!
你可以在这里找到完整的代码上传到GitHub。
结论
在本指南中,你学会了如何使用Puppeteer在登录状态下爬取亚马逊产品评论。你学会了如何登录,解析相关数据,并将其保存到CSV文件中。
为了继续练习,你可以使用分页来提取所有页面的所有评论。



Leave a Reply